[ Deutsch ] [ English ] [ Русский ]
Herzlich willkommen!
molekulartherapie.de
Theorie und modelltheoretische Therapieansätze zentralnervöser Erkrankungen
Zellprozessmodell
Probleme kann man niemals mit derselben Denkweise lösen, durch die sie entstanden sind.
- Albert Einstein -
2. Ein aggregiertes Zellmodell zur Zellschwachstellenanalyse
2.1 Vier Zellprozessbereiche und Ockhams Parsimonieprinzip▲
Eine grundlegende Hypothese aus dem ersten Kapitel lautet: Affektive Erkrankungen beruhen primär auf funktionellen Störungen von Nerven‑ und Gliazellen, die wiederum durch Störungen innerer Zellprozesse getriggert werden. Zellsprozessstörungen haben als Ursachen Affektiver Störungen damit eine wichtige sekundäre Bedeutung.
Diese Betrachtungsweise ist ein erster Schritt hin zu einem umfassenden Verständnis kausaler Ursachen neurologisch-psychiatrischer Erkrankungen. Nun bedarf es eines zweiten Schritts mit dem Ziel, Prozessstörungen auf Zellebene mittels Zellschwachstellenanalyse umfassend zu begründen.
Um im unübersichtlichen Zellstoffwechsel mit zahllosen Prozessen Schwachstellen sicher identifizieren zu können, wird ein Modell mit folgenden Eigenschaften benötigt:
- Das Modell muss ein Prozessmodell sein. Ursachen von Prozessstörungen sind nur prozessorientiert zu ermitteln.
- Bei der Konstruktion des Prozessmodells werden externe Einflüsse ausgeblendet, denn autonome Zellschwachstellen können nur in einem isolierten Modell identifiziert werden. Die Untersuchungen der Wirkungen von außen erfolgen zu einem späteren Zeitpunkt anhand dieses Modells.
- Zellprozesse sind in geeigneter Weise zu aggregieren. Das schafft Übersicht und fokussiert auf wichtige Abläufe. Die Komplexität muss auf ein notwendiges Minimum beschränkt werden, damit die Suche erfolgreich sein kann. Trotz dieser Aggregation muss das Zellprozessmodell vollständig sein und alle relevanten Vorgänge einer Zelle realistisch abbilden, damit das Prozessmodell im Einklang mit Ockhams Parsimonieprinzip steht.
Mit nur vier Prozessbereichen lässt sich ein Zellmodell entwickeln, das diesen Forderungen gerecht wird:
- Kern- und Zellteilung als grundlegende Prozesse und Ursprung jeder Zelle.
- Energieversorgung als eine Voraussetzung zur Durchführung aller Prozesse.
- Funktionsbezogene Prozesse für alle Vorgänge, die der Funktionserfüllung dienen.
- Die Proteinbiosynthese schafft die substanzielle Grundlage des Zellbetriebs.
ABBILDUNG 6: DIE VIER GRUNDLEGENDEN ZELLPROZESSBEREICHE
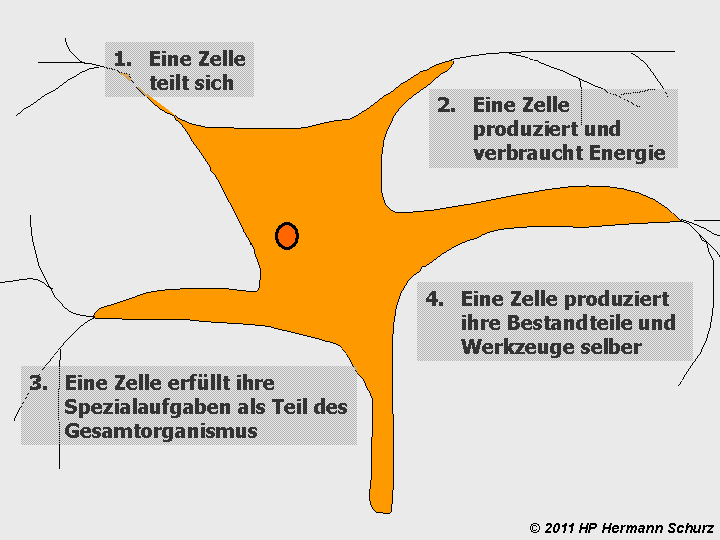
Abbildung 6: Alle Abläufe in einer Zelle lassen sich vier Prozessbereichen zuordnen.
Prozessbereich 1: Kern- und Zellteilung
Zellteilung ermöglicht Wachstum und Entwicklung: Aus einer Mutterzelle werden durch Teilung zwei identische Tochterzellen. Die von der Mutterzelle weitergegebenen 46 Chromosomen sind in menschlichen Zellen die Grundlagen aller Aktivitäten, denn sie enthalten die Baupläne (Gene bzw. Codes) verschiedener Substanzen, die für den Zellbetrieb unbedingt notwendig sind.
Die Zellkernteilung (Mitose) geht der Zellteilung voran. Zunächst werden die aus Desoxyribonukleinsäuren (DNA) bestehenden Chromosomen durch DNA‑Replikation verdoppelt: Die Doppelstränge („Doppel‑Helix“) werden entschraubt und geteilt, danach bildet sich an jedem Einzelstrang ein komplementärer Strang. Am Ende liegen idealerweise zwei schraubenförmige Doppelstränge mit identischen Erbinformationen vor. Animation 12 zeigt den Vorgang am Beispiel eines Bakteriums (→ Abschnitt 3.3).
Die dreiphasige DNA-Replikation wird durch Primer, Enzyme und Proteine gesteuert:
- Initiations- oder Startphase
Die Startmarkierungen erledigen Primer. Enzyme entschrauben danach die DNA‑Doppelstränge und trennen sie in einen Leitstrang und einen Folgestrang, die den Tochtersträngen als Vorlagen dienen. Danach beginnen DNA‑Polymerasen alpha mit dem Verdoppelungsvorgang beider DNA‑Stränge.
- Elongations- oder Verlängerungsphase
Die beiden Tochterstränge werden verlängert. Während der Leitstrang kontinuierlich in die Richtung der Aufspaltung verdoppelt wird und nur einen Primer als Starktmarkierung benötigt, wird der Folgestrang fragmentiert und diskontinuierlich in die andere Richtung verdoppelt. Jedes dieser als Okazaki‑Fragmente bezeichneten Teilstücke benötigt zur Verdopplung deshalb einen neuen Primer. Aufgrund der diskontinuierlichen Verknüpfung besteht der Tochter-Folgestrang am Ende aus einer Abfolge von Primern und Okazaki-Fragmenten, wobei jeder Primer eine Lücke darstellt, die beseitigt und durch DNA‑Bausteine ersetzt werden.
- Terminations- oder Schlussphase
Die DNA-Replikation wird mit Hilfe eines Proteins (Terminator utilization substance, kurz Tus‑Protein) beendet.
Der die nun verdoppelten Erbinformationen umschließende Zellkern wird danach geteilt, wobei der zweifache Chromosomensatz aufwändig getrennt und je ein Satz zur Seite gezogen wird. Beide neuen Zellkerne sind bei im Idealfall fehlerloser DNA-Replikation und Kernteilung mit vollständigen, identischen Erbinformationen bestückt.
Im zweiten Schritt erfolgt die Zellteilung (Zytokinese) durch Bildung neuer Zellhüllen, das Zellplasma mit den Zellorganellen wird aufgeteilt. Dafür werden ebenfalls Proteine und Enzyme benötigt. Für Transporte stehen MT‑basierte Motorproteine, wie Kinesin oder Dynein, zur Verfügung. Zellmembranen benötigen zum Aufbau u. a. Membranproteine.
Prozessbereich 2: Energieversorgung (Zellatmung)
Beim Energiestoffwechsel entsteht Energie durch die vollständige Umwandlung organischer in anorganische Stoffe. Dies geschieht bei Nervenzellen durch den Abbau (Oxidation) organischer Kohlenhydrate und Proteine bei gleichzeitigem Verbrauch von Sauerstoff. In Körperzellen wird Energie zusätzlich auch aus dem Abbau von Fettsäuren gewonnen, was bei Nervenzellen nicht möglich ist. Nervenzellen nutzen ausschließlich Glukose als Energieträger. Eine Ausnahme davon ist die Energienotversorgung bei Kohlenhydratemangel, die hier vernachlässigbar ist. Die Glukoseversorgung wird durch einen komplexen Mess- und Regelmechanismus (Blutzuckersteuerung) sichergestellt.
Der Energiestoffwechsel besteht aus drei Teilen: der anaeroben Glycolyse, dem Citratzyklus und der Atmungskette. Die beiden letzten Prozesse finden in komplexen Gewebeproteinen, den Mitochondrien, statt. Diese produzieren die Zellbrennstoffe Adenosintriphosphat (ATP) und Guanintriphosphat (GTP) und als Neben‑ bzw. Abbauprodukte u. a. Wärme (ca. 60% der Energie), Wasser und Kohlendioxid. Dafür werden viele Enzyme und Proteine benötigt, zum Beispiel Citrat‑Synthase, Adenylatcyclase, Aconitase, Phosphodiesterase oder Cytochrom c usf.
Mitochondrien besitzen als einzige Zellorganellen einen eigenen Erbinformationsträger, die mitochondriale DNA. Der größte Teil der für die Durchführung der Energieversorgung nötigen Informationen befindet sich aber auf den Chromosomen im Zellkern.
Prozessbereich 3: Funktionsbezogene Prozesse
Jede Zelle erfüllt individuelle Funktionen: Nerven verarbeiten Reize, Gliazellen müssen Nerven stützen, voneinander isolieren oder für den An- bzw. Abtransport von Nähr- und Schadstoffen sorgen. Auch dafür werden Enzyme und Proteine benötigt. Gewebeproteine dienen dem Aufbau von Zellorganellen, Dendriten (Nervenzellenfortsätze für die Signalaufnahme), Axonen, Synapsen oder der Myelinschicht der Gliazellen.
Verschiedene Enzyme und Proteine dienen der Steuerung neuronaler Hauptfunktionen, indem sie an der Synthese monoaminer Neurotransmitter oder von Neuropeptiden mitwirken. Das Enzym Monoaminoxidase (MAO) baut monoamine Neurotransmitter nach der Reizübertragung zwischen den Nervenzellen ab.
Prozessbereich 4: Proteinbiosynthese
Aufgrund ihrer Komplexität und wegen der Bedeutung als Ursprung sämtlicher Peptide und Proteine wird die Proteinbiosynthese im Abschnitt 2.2 ausführlicher dargestellt.
2.2 Proteinbiosynthese und Genregulation▲
Die Proteinbiosynthese dient der Herstellung körpereigener Enzyme und Proteine, die aus miteinander verketteten Aminosäuren bestehen. Es gibt 20 verschiedene Aminosäuren, die hauptsächlich durch Nahrungsproteine zugeführt werden, zwölf Aminosäuren kann der Körper auch selber herstellen (→ Abschnitt 2.3.5 f.).
Enzyme und Proteine gehören zur Gruppe der Peptide und werden u. a. nach der Anzahl ihrer Aminosäuren (Kettenlänge) unterschieden:
- Verbindungen von nur zwei Aminosäuren sind Dipeptide.
- Tripetide sind Verbindungen dreier Aminosäuren.
- Verbindungen ab vier bis weniger als zehn Aminosäuren werden Oligopeptide genannt.
- Polypeptide sind Verbindungen von zehn bis hundert Aminosäuren, darunter viele Enzyme und Neuropeptide.
- Ein Makropeptid mit mehr als hundert Aminosäuren wird auch als Protein bezeichnet. Dazu zählen vor allem die komplexen Gewebeproteine und einige Neuropeptide.
Spezialisierte Zellen benötigen spezielle Peptide und haben unterschiedliche Peptidprofile. Leberzellen nutzen andere Peptide als Nierenzellen für ihre Spezialfunktionen. Auch im selben Organ können Zellen hochdifferenziert sein, so auch im Gehirn: Eine Mittelhirnzelle nutzt zum Teil andere Peptide als eine Zwischenhirnzelle. Selbst in einer so kleinen Region wie der des Mittelhirns haben Neuronen unterschiedliche Pepditanforderungen.
Die Proteinbiosynthese nutzt zur Aminosäurenverkettung Informationen auf der DNA, die mit nur vier verschiedenen Nukleinbasen verschlüsselt sind: Adenin, Cytosin, Guanin und Thymin. Ein Triplett ist als Abfolge dreier Nukleinbasen der Code für die Verkettung einer Aminosäure. Da nur zwanzig Aminosäuretypen zu codieren sind, reichen vier Basenarten mehr als aus. Mathematisch könnten mit einem Triplett sogar 4³ = 4 x 4 x 4 = 64 Aminosäuretypen verschlüsselt werden. Da auf der DNA in diesem Zusammenhang auch Befehle zu codieren sind und einige Aminosäuretypen redundant mit mehreren Codes verschlüsselt sind, werden alle 64 Möglichkeiten genutzt.
Ein Peptid mit 28 Aminosäuren wird demnach mit einer Abfolge von 28 Tripletts codiert. Die Triplettabfolge eines vollständigen Peptids wird als Gen bezeichnet.
Im Zellkern jeder Zelle befinden sich auf 46 DNA‑Strängen die Gene aller Peptide, die ein Organismus benötigt. Einer Zelle muss es daher gelingen, ausschließlich die speziellen Gene zur Synthese von Peptiden zunutzen, die sie für ihre Funktionen benötigt. Dafür muss eine Zelle in der Lage sein, die Gesamtheit der Gene in ihrem Zellkern zu regulieren. Die Genregulation ist eine Hauptaufgabe der Proteinbiosynthese.
Transkription und Translation
Die Proteinbiosynthese erfolgt in zwei Teilen: Zunächst die Transkription, bei der ein Gen von der Zell‑DNA abgelesen wird und danach die Translation, welche die abgelesenen Informationen in Peptide übersetzt. Hier kommen Ribonukleinsäuren (RNA) ins Spiel, die ‑ wie die DNA ‑ vier Nukleinbasen verwenden.
Bei der Transkription wird eine mRNA (messenger‑RNA bzw. Boten‑RNA) als komplementäres Abbild eines Gens synthetisiert. Wie ein Farbnegativ repräsentiert eine codierende mRNA ein Gen. Bei der Translation (Übersetzung) der mRNA in ein Peptid werden nicht-codierende tRNA-Hilfsmoleküle (Transfer‑RNA) benötigt. Die Videos 1 und 2 zeigen beide Prozesse anschaulich.
TABELLE 1: DNA-NUKLEINBASEN UND DAZU KOMPLEMENTÄRE RNA-NUKLEINBASEN
DNA-Basen |
RNA-Basen |
|---|---|
Adenin (A) |
Uracil (U) |
Cytosin (C) |
Guanin (G) |
Guanin (G) |
Cytosin (C) |
Thymin (T) |
Adenin (A) |
Tabelle 1: Es gibt fünf Nukleinbasen. DNA und RNA verwenden davon jeweils vier als Bausteine und unterscheiden sich u. a. in der Verwendung unterschiedlicher Komplementärbasen zu Adenin.
DNA und RNA unterscheiden sich in mehreren Aspekten voneinander, nicht nur funktional und durch die Verwendung der Nukleinbase Thymin (DNA) anstelle von Uracil (RNA). Sie haben auch eine minimal andere Struktur ihres Kohlenhydratanteils (DNA mit Desoxyribose, RNA mit Ribose), und die mRNA ist einsträngig im Gegensatz zur doppelsträngigen DNA.
VIDEO 1: EINFÜHRUNG TRANSKRIPTION
Video 1: Eine verständliche Erläuterung der wesentlichen Zusammenhänge. Der Begriff „Botenstoff“ ist nicht zu verwechseln mit den Botenstoffen für die Reizübertragung zwischen den Nervenzellen, die im ersten Kapitel erläutert wurden; hier ist damit die Boten‑RNA (mRNA bzw. messenger‑RNA) gemeint. Gegen Ende wird auf die Genregulation verwiesen. (Quelle: YouTube, https://www.biotechnologie.de)
Die mRNA wandert nach der Transkription vom Zellkern heraus ins Zytoplasma und wird dort von Ribosomen in ein Peptid übersetzt. Dieser als Translation bezeichnete Prozess ist der zentrale Vorgang der Proteinbiosynthese.
VIDEO 2: EINFÜHRUNG TRANSLATION
Video 2: Die Darstellung beschränkt sich auf wichtige Zusammenhänge. Auch hier ist mit „Botenstoff“ die Boten-RNA (mRNA) gemeint. (Quelle: YouTube, https://www.biotechnologie.de)
2.2.1 Transkription im Detail und mRNA-Processing
Der als Transkription bezeichnete Ableseprozess verläuft in vier Phasen und wird mit zahlreichen unterschiedlichen Peptiden gesteuert.
Initiation (1)
Ein Promotor‑Code auf der DNA markiert den Beginn eines zu transkribierenden Gens und wird mittels eines Transkriptionsfaktors gefunden. Dazu durchforsten zahlreiche von ihnen die doppelsträngige DNA systematisch (→ Animation 1), um an geeigneten Promotoren anzudocken. Ein Repressor unmittelbar hinter einem Promotor kann das Andocken verhindern: Das Gen wird dann entweder gar nicht oder gerade nicht benötigt. Mit zahlreichen Repressoren (Helix‑Loop‑Proteine, Zinkfingerproteine, Leucin‑Zipper‑Proteine usw.) sind damit weitere Peptide an der Initiation beteiligt.
Transkriptionsfaktoren, Repressoren und deren Aktivitäten werden der Genregulation zugeordnet. Da Zellen spezialisierte Einheiten sind, benötigen sie nur einen Bruchteil der Gene, die ihnen auf der DNA im Zellkern mit 46 Chromosomen zur Verfügung stehen. Um für sie notwendige Gene herauszusuchen, verfügt eine Zelle über umfangreiche Instrumentarien regulativer Prozesse und Moleküle, von denen Transkriptionsfaktoren und Repressoren einen kleinen Teil darstellen.
ANIMATION 1: TRANSKRIPTIONSFAKTOR AUF DER SUCHE NACH SEINEM PROMOTOR
Animation 1: Es gibt nach derzeitigem Wissen etwa 1.500 unterschiedliche Transkriptionsfaktoren, die in Zellen systematisch und effizient nach zu transkribierenden Genen suchen und nicht nach einem ineffizienten „Try‑and‑error‑Prinzip“. Sie nutzen das Rückgrat der DNA und spulen sich bis zum von ihnen gesuchten Promotor vor. Dabei können sie auch Hindernisse, beispielsweise Repressor‑Proteine, überwinden, mit anderen Proteinen interagieren oder von einem DNA‑Strang zu einem anderen springen. (Quelle: YouTube/Stroma Studios, Seattle, WA, USA, http://www.stromastudios.com)
An der Andockstelle des Transkriptionsfaktors wird ein Proteinkomplex eingebunden, der aus einer RNA‑Polymerase II und weiteren Enzymen besteht, beispielsweise einer Helikase. Diese als Transkriptioninititations‑Komplex bezeichnete Struktur harrt dort dem Start des Kopierprozesses.
Elongation (2)
Ein Aktivator‑Protein startet die Transkription. Vom Promotor beginnend legt die RNA‑Polymerase II jeweils bis zu 20 Nukleinbasen frei, an denen sich komplementäre RNA‑Basen anlagern und verbindet diese zu einer Basenkette (→ Animation 2). Für den Kopiervorgang werden noch weitere Peptide benötigt, zum Beispiel TBP.
Termination (3)
Ein Terminator-Code auf der DNA gibt der RNA‑Polymerase II den Stoppbefehl, da das Gen nun fertig kopiert ist. Diese Kopie ist als mRNA das vollständige, komplementäre Abbild des Gens (→ Animation 2).
Die RNA‑Polymerase II erkennt den Terminator mit Hilfe weiterer Peptide. Das Enzym Exonuklease schneidet die mRNA danach ab, der Proteinkomplex TREX ist ebenfalls für die Beendigung des Prozesses notwendig.
ANIMATION 2: ELOGATION UND TERMINATION DER TRANSKRIPTION
Animation 2: Ein Transkriptionsfaktor hat die gesuchte Bindungsstelle auf der DNA gefunden hat. Es erfolgt die Integration der RNA‑Polymerase II und weiterer Proteine zum Transkriptioninitiations‑Komplex. Ein Aktivator‑Protein startet die Transkription und die RNA‑Polymerase II rast über die DNA, teilt deren Doppel‑Helix jeweils für ein kleines Stück und synthetisiert die mRNA. Die RNA‑Basen strömen von links in die Polymerase und die mRNA‑Kette schlängelt sich nach draußen. (Quelle: YouTube/DNA Learning Center, http://www.dnalc.org)
Rückführung der Initiation (4)
Der Transkriptionsprozess ist beendet, wenn sich die RNA‑Polymerase II vom DNA‑Strang trennt und dieser wieder zusammen mit seinem komplementären Strang in der Doppel‑Helix mit der ursprünglichen Basenpaarung vorliegt.
Die RNA‑Polymerase II verbleibt im Plasma des Zellkerns und bewegt sich dort umher, bis sie zufällig oder gesteuert wieder in Kontakt mit der DNA kommt und erneut eine Transkription beginnt.
Modifizierung der unreifen mRNA (mRNA‑Processing) und Transport ins Zytoplasma
Die mRNA hat sich ‑ zusammen mit der RNA‑Polymerase II ‑ vom DNA‑Strang gelöst, weist aber noch überflüssige Basensequenzen auf, und es fehlen Markierungen für die nächsten Schritte. Die als unreif bezeichnete mRNA bzw. pre‑messenger‑RNA wird noch im Zellkern mit Hilfe weiterer Enzyme bearbeitet.
Die Markierungen der unreifen mRNA bestehen aus zwei Maßnahmen. Parallel zur Elongation wird eine Kappe angebracht (Capping) und nach Beendigung des Kopiervorgangs erfolgt eine Verlängerung mit zahlreichen Adenin‑Basen (Polyadenylierung), die auch als polyA‑Kette bezeichnet wird. Verschiedene Peptide kommen zum Einsatz, beispielsweise Cleavage‑Faktoren, Stabilisatoren, die PolyA‑Polymerase zum Anbringen der polyA‑Kette und Proteine zur Verlängerung, beispielsweise CPSF oder PABPN1 (→ Animation 3).
ANIMATION 3: CAPPING UND POLYADENYLIERUNG
Animation 3: Dieser Trickfilm zeigt das Capping und die Polyadenylierung. Das parallel stattfindende Spleißen wird in Animation 4 gezeigt. (Quelle: YouTube, http://vcell.ndsu.edu/public)
Ebenfalls noch während des Kopiervorgangs (co‑transkriptional) werden nicht notwendige Basenfolgen ‑ Introns genannt ‑ aus der unreifen mRNA herausgetrennt (→ Animation 4). Dieser als Spleißen (Splicing) bezeichnete Prozess wird von Splicosomen durchgeführt und im Kapitel 3 noch ausführlicher thematisiert.
ANIMATION 4: SPLEISSEN (SPLICING)
Animation 4: Das Beispiel zeigt die Tätigkeit der Spleißosomen genannten Proteinkomplexe. Schon während der eigentlichen Transkription werden die grün dargestellten Introns aus der unreifen mRNA herausgeschnitten und die offenen Enden der mRNA miteinander verbunden. Ein menschliches Gen hat im Schnitt ca. 5 bis 6 Introns. (Quelle: YouTube/DNA Learning Center, http://www.dnlac.org)
Die fertig modifizierte mRNA ‑ auch reife mRNA genannt ‑ gelangt nun mittels Transportproteinen durch die Zellkernporen in das Zytoplasma.
2.2.2 Translation
Nachdem die reife mRNA das Zytoplasma erreicht hat, erfolgt die Übersetzung ihres Codes in eine Sequenz von Aminosäuren mit Hilfe zahlreicher Peptide und einer speziellen RNA: der Transfer‑RNA (tRNA). Die wichtigsten Peptide sind in den folgenden Darstellungen wieder durch Fettschrift hervorgehoben.
Aminosäuren können sich nicht direkt an die mRNA heften. Dazu werden tRNA als Trägersubstanzen benötigt, die Aminosäuren binden, die dazugehörigen Basensequenzen auf der mRNA erkennen und dort ankoppeln.
Drei mRNA‑Nukleinbasen sind ein Codon. Jede tRNA verfügt über ein dazu passendes Anticodon mit drei komplementären Basen, mit dem sie an das mRNA‑Codon andockt. Mit im Gepäck: die dazugehörige Aminosäure, die vorher mit Hilfe einer bestimmten AtRNA‑Synthetase an die tRNA angehängt wurde.
Trotz 64 Verschlüsselungskombinationen verfügen Zellen nur über maximal 41 verschiedene Anticodons. Die Ketten der Aminosäuren werden dennoch korrekt gebildet. Der britische Forscher Francis Crick erklärte das im Jahr 1966 mit seiner Wobble-Hypothese, nach der Basenpaarungen an der jeweils dritten Stelle variieren können.
Die Translation hat drei Phasen: Initiation, Elongation und Termination.
Initiation (1)
Ribosomen sind Kerninstrumente der Initiationsphase. Es handelt sich um Proteinkomplexe, die zusammen mit ribosomaler RNA (rRNA) die Paarung mRNA‑tRNA ermöglichen. Im Ribosom findet die Verknüpfung des tRNA‑Anticodons mit dem dazu komplementären mRNA‑Codon statt.
Startcodes auf der mRNA signalisieren der ersten tRNA die Andockstelle. Daran sind viele weitere Proteine beteiligt, sie werden als Initiationsfaktoren oder kurz eIFs bezeichnet. Derzeit sind bei höheren Organismen elf verschiedene eIFs bekannt: eIF1, eIF2, eIF3 usf.
Elongation (2)
Die Peptidkette wird verlängert, indem sich weitere tRNA‑Anticondons an mRNA‑Codons anlagern. Mehrere Elongationsfaktoren, zum Beispiel EF‑Tu, EF‑Ts und EF‑G, steuern den Prozess. Die Aminosäuren lösen sich von der tRNA und werden mit Hilfe der Peptidyltransferase miteinander verkettet.
Nach der Aminosäureabgabe haben die tRNA ihre Funktionen erfüllt. Sie lösen sich vom mRNA‑Codon und verlassen unbeladen das Ribosom.
Termination (3)
Ist der Terminationscode auf der mRNA erreicht, endet die Translation, und das neu gebildete Peptid löst sich vom Ribosom. Die mRNA trennt sich vom Ribosom, wird abgebaut oder es erfolgt deren Weitergabe an das nächste Ribosom zwecks erneuter Translation. Den Prozess steuern als Terminationsfaktoren bezeichnete eRFs. Bei höheren Organismen sind bisher drei bekannt: eRF1, eRF2 und eRF3.
Alternative Animationen der Translation
Animation 5 reduziert auf das Wesentliche. Die alternative Animation 6 soll den Vorgang „in Echtzeit“ darstellen.
ANIMATION 5: TRANSLATION OHNE DETAILS
Animation 5: Eine einfache schematische Darstellung. Aufbau und Funktionen des Ribosoms werden genauer erklärt. Die Basenfolge AUG ist das Signal (Startcodon) zur Koppelung mit dem Ribosom. Dann erfolgt der Aufbau der Aminosäurenkette mittels tRNA und den sich daran befindlichen Aminosäuren. Das Terminationscodon UAG beendet den Prozess mit einem Terminationsfaktor. (Quelle: YouTube)
ANIMATION 6: DETAILLIERTERE DARSTELLUNG DER TRANSLATION
Animation 6: Eine weniger schematische Darstellung der Translation, welche die Abläufe in Echtzeit simulieren soll. (Quelle: YouTube/DNA Learning Center, http://www.dnalc.org)
Proteinstrukturbildung zum Abschluss der Proteinsynthese
Unmittelbar nach der Translation sind die neu entstandenen Aminosäurenketten in ihren Primärstrukturen noch nicht einsatzbereit. Dazu müssen sie sich in eine räumliche Sekundärstruktur oder Tertiärstruktur falten. Einige Tertiär-Proteinstrukturen verbinden sich darüber hinaus noch zu einer gemeinsamen Quartärstruktur. Nur räumliche Proteingebilde sind zur Funktionserfüllung in der Lage.
Dafür benötigen bestimmte Aminosäurenketten einiges an Hilfe. Kurze Ketten falten sich selber, aber bei den längeren besteht die Gefahr, dass sie sich untereinander ungesteuert verbinden, aggregieren und somit funktionsuntüchtig werden. Chaperone und Chaperonine ‑ beides ebenfalls komplexe Proteingebilde ‑ verhindern das, indem sie bei der Sekundär- und Tertiärstrukturbildung als Faltungshelfer unterstützen.
ANIMATION 7: PROTEINSTRUKTURBILDUNG
Animation 7: Der Film zeigt verschiedene Auffaltungsprozesse zu funktionsfähigen Peptiden. Im ersten Teil werden die Unterschiede der vier Grundstrukturen erklärt, im zweiten Teil die für die Strukturbildung wesentlichen Abläufe. Die Translation erfolgt im Beispiel mit zwei Ribosomen, die nacheinander dieselbe mRNA auslesen. Tatsächlich durchläuft eine mRNA häufig mehrere Ribosomen hintereinander mit dem Ziel, die Peptidbildung zu beschleunigen. Findet kein Abtransport der aus den Ribosomen austretenden Ketten statt, können sich diese schon kurz nach ihrer Entstehung in funktionsuntüchtigen „Peptidschrott“ verwandeln. Um diese Verklumpung zu verhindern, werden die Primärketten sofort nach dem Austritt von Chaperonen in Empfang genommen, um eine korrekte Faltung zu ermöglichen. Diese Chaperone sind auch in der Lage, fehlgefaltete Peptidketten zu reparieren oder ‑ falls eine Reparatur nicht mehr möglich ist ‑ die fehlerhaften Ketten Proteasom‑Proteinen zuzuführen, die sie auflösen und in einzelne Aminosäuren recyceln. Sehr lange Aminosäurenketten (bis zu 600 Aminosäuren) benötigen zusätzlich ein Chaperonin. Die Aminosäurenketten werden von Chaperonen in einen Chaperonin‑Zylinder befördert, in dem sie sich zu funktionsfähigen Proteinen falten. (Quelle: YouTube/Max‑Planck‑Gesellschaft, © www.mpg.de/2014, http://www.mpg.de)
2.2.3 Proteintransport (Protein targeting) und weitere Proteinmodifikationen
Mit der Translation und dem anschließenden Auffaltungsprozess ist die Proteinbiosynthese im engeren Sinne beendet. Einige Peptide verbleiben im Zytoplasma, andere müssen noch zu den Stellen in der Zelle gelangen, an denen sie gebraucht werden. Das gilt für die verschiedenen Zellorganellen oder entferntere Bereiche wie Zellkern oder Nervenzellenfortsätze bei Neuronen. Manche Enzyme oder Proteine erfüllen ihre Funktionen auch außerhalb der Zellmembran, zum Beispiel Insulin.
Der Transport ist von Enzymen und Proteinen abhängig. Dazu zwei Beispiele:
- Der Proteinkomplex SRP (Signal recognition particle) sorgt dafür, dass Peptide zu einer bestimmten Zellstruktur, dem Endoplasmatischen Retikulum, transportiert werden.
- Das Enzym MPP (Mitochondrial processing peptidase) ist beim Peptidtransport zu den Mitochondrien beteiligt.
Parallel zum Transport an den Einsatzort werden viele Proteine und Enzyme durch weitere Prozesse auch in ihrer Struktur verändert, damit sie in Aktion treten können. Diese Vorgänge finden zum Teil kurz nach der Synthese an den Ribosomen, nach der Chaperonin-Auffaltung oder auch außerhalb der Zellen statt. In den meisten Fällen sind jedoch Zellorganellen im Zytoplasma, beispielsweise das Endoplasmatische Retikulum oder der Golgiapparat, Orte für co- oder posttranslationale Modifikationen. Auch hier steuern Enzyme und Proteine das Geschehen.
2.2.4 RNA und Genregulation
Nachdem die DNA‑Doppelhelix im Jahre 1953 und die grundlegenden Prozesse der Proteinbiosynthese entdeckt wurden, blieben Modelle und Prozessverständnis lange Zeit unverändert. DNA galten als Hauptakteure, RNA waren die langweiligen Hilfsmoleküle, die mechanistisch Gene kopieren: DNA waren die Köche, RNA die Kellner.
Die Modelle wurden jedoch von Beginn an als fragmentarisch und unbefriedigend wahrgenommen. Schließlich konnte mit ihnen niemand erklären, wie es spezialisierten Zellen überhaupt möglich ist, aus der Gesamtheit aller Gene im Zellkern immer genau die für sie passenden herauszusuchen, während eine unvergleichlich höhere Anzahl von Genen einfach links liegen gelassen wird.
Ein weiteres Rätsel war die geringe Menge von nur ca. 25.500 Genen, der eine riesige Zahl von Codes ‑ nämlich die restlichen 98% der gesamten DNA ‑ gegenüberstehen, denen keine Funktionen zugeordnet werden konnten, und die deshalb zunächst als „Junk‑DNA“ bezeichnet wurden.
Einiges klärte sich zunächst durch die Entdeckung von Transkriptionsfaktoren und Repressoren. Jetzt konnte auf Peptide bzw. Proteine verwiesen werden, die den Genauswahlprozess gezielt regulieren (→ Abschnitt 2.2.1). Ebenfalls wurden Histone, die bis in die 1990er Jahren lediglich als DNA‑Verpackungselemente galten, als für die Genregulation bedeutsame Proteine identifiziert, die u. a. die Höhe der Transkriptionsrate von Genen bestimmen.
Man fand heraus, dass Steroidhormone mit Hilfe von Rezeptorpeptiden die Transkription steuern und damit weitere wichtige genregulative Elemente darstellen.
Dennoch reichten auch diese Erklärungen nicht aus, beispielsweise um die Frage zu beantworten, wie Zellen es schaffen, immer genau über die für ihren spezifischen Bedarf passenden Regulationsproteine zu verfügen. Auch erschien die Anzahl von Peptiden und Proteinen (und Hormonen) zur Genregulation als zu gering, um komplexe Organismen zu steuern.
In den 1990er Jahren kam es dann ‑ zum Teil unabhängig voneinander ‑ zu verschiedenen Entdeckungen, die dieses starre DNA-Weltbild ins Wanken bringen sollten.
Entdeckung der RNA-Interferenz (RNAi) mit small interfering RNA (siRNA)
Im Jahre 1987 versuchte ein Pflanzenforscherteam um Carolyn Napoli und Richard Jorgensen, die violette Blütenfarbe von Petunien zu verstärken. Sie brachten dazu eine zusätzliche Kopie des Gens für die Synthese des Blütenfarbstoffs in die Pflanzenzellen ein. Statt einer Farbintensivierung veränderten die Petunien der nächsten Generation zur Überraschung der Wissenschaftler ihre Farbe in eine Mischung aus blassem Violett und Weiß, manche waren gar komplett weiß. Die Pflanzen schienen gegen das Fremdgen einen Abwehrmechanismus in Gang gesetzt zu haben, der aber auch das natürliche Gen der Pflanzen in seiner Funktion behinderte. Wie die Pflanzenzellen dabei vorgehen und ob bzw. welche Rolle hier RNA spielen, war zum damaligen Zeitpunkt noch völlig unbekannt, aber die Sache kam ins Rollen.
In den darauffolgenden Jahren beschäftigten sich verschiedene Forscherteams mit diesem und vergleichbaren Phänomenen. Die Zusammenhänge und grundlegende Abläufe konnten so nach und nach entschlüsselt werden.
1998 wiesen die US‑amerikanischen Wissenschaftler Andrew Fire (Biologe) und Craig Mello (Biochemiker) einen Genstummschaltungsprozess bei Fadenwürmern nach (Quelle: Driver, Fire, Mello et al., Potent and specific genetic interference by double-stranded RNA in Caenorhabditis elegans, Nature Journal No. 391, 2/1998, http://www.ncbi.nlm.nih.gov/...). Sie schleusten in die Zellen der Fadenwürmer doppelsträngige RNA‑Moleküle ein, deren Basenfolgen mit einem Gen zur Herstellung von Muskelprotein übereinstimmen. Nachdem zuvor durchgeführte Experimente mit einzelsträngiger RNA keine Folgen zeigten, konnte das Gen nun erfolgreich stummgeschaltet und die Herstellung des Proteins unterbunden werden. Es stellte sich heraus, dass die zur Proteinsynthese notwendige mRNA zerstört wurde und der Mechanismus auf diese Weise die Translation des Muskelproteins stoppte. Aber auch jetzt war noch nicht genau klar, wie die doppelsträngigen RNA zu diesem Ergebnis führen konnten.
Einige Jahre vor der Veröffentlichung von Fire und Mello versuchte der britische Pflanzengenetiker David Baulcombe an der Universität Norwich Gemüsepflanzen ‑ in diesem Falle Kartoffeln ‑ gentechnisch gegen Viruserkrankungen zu immunisieren. Baulcombe gelang es, ein doppelsträngiges RNA‑Virusgen in Kartoffelzellen einzubringen, worauf diese gegen das Virus resistent wurden. Nachforschungen ergaben jedoch, dass das eingebrachte RNA-Gen stummgeschaltet worden war und seine Aufgaben gar nicht erfüllen konnte. Warum die Kartoffeln dennoch gegen das Virus resistent wurden, konnte sich der Wissenschaftler zunächst nicht erklären, aber es musste einen Mechanismus geben, der sowohl die sofortige Ausschaltung des eingeschleusten Gens betreiben als auch gegen das Virus immun machen konnte. Ein Kollege von Baulcombe, Andrew Hamilton, fand schließlich ein kleines RNA‑Molekül, das dafür verantwortlich war. Allerdings informierten die beiden britischen Forscher nicht sofort über ihre bedeutende Entdeckung, sondern prüften langwierig, ob die Ergebnisse hieb- und stichfest wiederholbar waren und veröffentlichten Ihren Fachartikel 1999 in der Zeitschrift Science, also ein Jahr später als Fire und Mello.
Die dann folgenden Versuche, die RNA‑Strategie auch bei höheren Organismen anzuwenden, funktionierten zunächst nicht, Zellen starben als Reaktion auf längere doppelsträngige RNA ab, es setzte die Apoptose ein ‑ der programmierte Zelltod. Ein deutscher Molekularbiologe, Thomas Tuschl, fand zusammen mit Sayda Elbashir heraus, dass die Länge der RNA‑Doppelstränge für den Mechanismus entscheidend ist und diese idealerweise etwa 20 bis 22 Nukleotide aufweisen sollten und veröffentlichte die Ergebnisse im Jahre 2001.
Später wurde der grundlegende Prozess als RNA‑Interferenz (abgekürzt RNAi) bezeichnet, was mit „RNA‑Wechselwirkung“ ins Deutsche übersetzt werden kann, während für die dazu erforderlichen niedermolekularen RNA der Begriff small interfering RNA (siRNA) geprägt wurde. Alternativ wird die RNA‑Interferenz auch RNA silcening genannt, zu Deutsch „RNA‑Stummschaltung“.
Fire und Mello erhielten schon im Jahre 2006 den Nobelpreis für Medizin, wohingegen sowohl die Briten Baulcombe und Hamilton und ihre Entdeckung der immunologischen RNAi als auch Thomas Tuschl leer ausgingen, was damals viel kritisiert wurde.
VIDEO 3: EINFÜHRUNG RNA-INTERFERENZ
Video 3: Diese vereinfachte Darstellung der RNA-Interferenz (RNAi) als Grundlage experimenteller Prozesse beschränkt sich auf wichtige Zusammenhänge. Auch hier ist mit „Botenstoff“ die Boten-RNA (mRNA) gemeint. (Quelle: YouTube, https://www.biotechnologie.de)
RNAi am Beispiel der Virenabwehr mit siRNA
Die Virenbekämpfung mit RNA ist eine gängige Strategie von Zellen, denn die meisten hochansteckenden Virenarten verwenden doppelsträngige RNA (dsRNA) als Erbgut und keine DNA. Um der Viren Herr zu werden, benötigen Zellen deshalb einen auf RNA-Molekülen basierenden Abwehrprozess: Die RNA-Interferenz (RNAi) mit Hilfe kurzkettiger siRNA-Molekülen.
Das RNA-Virenerbgut dringt in die Wirtszelle ein, wird als fremd erkannt und bekämpft: Enzyme schneiden die fremde dsRNA in mehrere Fragmente mit einer Länge von ca. 22 Nukleotiden. Dann trennen RIS‑Proteine (RNA‑induced‑silencing protein), auch als Argonautenprotein bezeichnet, die kurzen doppelsträngigen RNA‑Fragmente in einzelne RNA-Stränge, wobei jeweils der Leitstrang in den RIS‑Proteinen verbleibt, die zweiten komplementären Stränge werden nicht benötigt und abgebaut. Nun verfügt die Zelle über geeignete Einzelstrang-siRNA, mit deren Hilfe sie die Virenattacke abwehren wird.
Nach Verbindungen mit weiteren Proteinen werden die RIS‑Proteine zu RISCs (RNA‑induced‑silencing complex). Noch verbliebene aktive oder neu hinzugekommene Viren‑RNA sind dank der RISCs nun nicht mehr in der Lage, ihre zellschädigenden Fremdpeptide bzw. -proteine herzustellen, denn die mit einer Leitstrang‑siRNA „bewaffneten“ RISCs erkennen nun komplementäre Basenfolgen zellfremder mRNA, spalten diese oder blockieren direkt an der feindlichen mRNA die Translation in ein zellfremdes Peptid bzw. Protein.
Die Zelle hat sich damit doppelt gegen Vireneindringlinge abgesichert, indem sie deren Erbgut zerstört, vor allem aber mit daraus gewonnenen siRNA‑Partikeln aktiv unerwünschte Fremd‑mRNA an der Translation hindert. Jedoch ist auch die zelleigene mRNA dem Risiko eines Angriffs der RISCs ausgesetzt (→ Animation 8).
Die kurzkettigen siRNA‑Moleküle werden den nicht‑codierenden RNA (ncRNA) zugeordnet, um sie von den codierenden mRNA abzugrenzen. Bis zu ihrer Entdeckung galten nur die Transfer‑RNA (tRNA) und die ribosomalen RNA (rRNA) als nicht‑codierend.
Eine künftige medizinische Anwendung dieses natürlichen immunologischen Prinzips wäre die Verwendung synthetischer oder labortechnisch manipulierter siRNA, mit denen virale Infektionskrankheiten behandelbar sein könnten. Es gibt vielversprechende Ansätze in der Krebs‑ und AIDS‑Therapie.
Entdeckung der micro-RNA (miRNA)
Die Veröffentlichungen von Baulcombe und Hamilton bzw. Fire und Mello oder Thomas Tuschl waren nur erste Schritte hin zu einem biologischen Paradigmenwechsel. Es stellte sich nämlich heraus, dass die RNA‑Interferenz mehr als nur immunologische oder experimentelle Aufgaben zu erfüllen in der Lage ist, da Zellen den RNAi‑Prozess auch zur Steuerung ihrer eigenen Proteinbiosynthese anwenden. Schon einige Zeit vorher veröffentlichten die ebenfalls aus den USA stammenden Forscher Victor Ambros (Biologe) und Gary Rufkun (Biophysiker) im Jahre 1993 ihre Erkenntnisse über ein in Zellen von Fadenwürmern hergestelltes kurzkettiges RNA‑Molekül, das zur Regulation bzw. Modulation der Genexpression genutzt wird. Diese ncRNA-Moleküle waren die ersten Vertreter einer mittlerweile als micro‑RNA (miRNA) bezeichneten Gruppe von RNA, die auf nicht absehbare Zeit die interessantesten Gegenstände biologischer und medizinischer Forschung sein werden. Denn sie sind nicht nur in den Zellen von Fadenwürmern aktiv, sie haben zentrale Funktionen bei der zellspezifischen Genregulation in allen Zellen sämtlicher Spezies ‑ auch beim Menschen. Die Medizin hat daher hohe Erwartungen bezüglich ihres therapeutischen Potentials.
Seither werden immer mehr interferierende miRNA‑Moleküle entdeckt, jedoch klären sich die mit ihnen verbundenen Genregulationsmechanismen nur langsam. Die Vorstellung von der DNA als Koch und der RNA als Kellner sollte damit dennoch endgültig überholt sein.
Ambros und Rufkun erhielten 2024 den Medizin‑Nobelpreis ‑ also 18 Jahre später als Fire und Mello ‑, obwohl sie ihre Arbeit fünf Jahre vor diesen veröffentlichten und davon auszugehen ist, dass sie schon kurz nach der Publikation in der Fachwelt mit großem Interesse registriert wurde.
ANIMATION 8: RNA-INTERFERENZ ZUR VIRENABWEHR UND GENREGULATION
Animation 8: Die Animation zeigt die RNA‑Interferenz (RNAi) mit Hilfe von siRNA‑Molekülen als immunologischen Prozess und zur Regulation eigener Gene mittels miRNA, allerdings an einigen Stellen missverständlich. Die Codes der miRNA sind immer auf der Zell‑DNA lokalisiert und ermöglichen die Modulation der eigenen Proteinsynthese. Demgegenüber gibt es keine siRNA‑Codes auf der DNA, denn siRNA basieren auf der Fremd‑RNA von Viren oder gelangen experimentell von außen in die Zelle. Darüber hinaus gibt es weitere Unterschiede zwischen der immunologischen und genregulativen RNAi, die unerwähnt bleiben, für das grundlegende Verständnis jedoch nicht entscheidend sind. Strukturell unterscheiden sich siRNA und miRNA nicht wesentlich, jedoch hinsichtlich ihrer spezifischen Bindungsfähigkeiten. Während siRNA nur an exakt korrespondierende mRNA binden, sind miRNA wesentlich flexibler. (Quelle: YouTube/Spektrum der Wissenschaft, http://www.spektrum.de)
RNAi am Beispiel der Regulation eigener Gene mit miRNA
Die Baupläne für miRNA sind auf der Zell-DNA lokalisiert und werden dort transkribiert. Dabei handelt es sich auch um jene DNA‑Basensequenzen, die bis in die 1990er Jahre als rätselhaft galten, weil deren Nutzen sich niemandem erschloss und als Junk-DNA verunglimpft wurden.
Details des Prozesses der miRNA‑Synthese und der anschließenden RNA-Stummschaltung sind mittlerweile bekannt:
- Hauptsächlich verantwortlich für das Ablesen bzw. die Transkription der miRNA-Codes von der DNA sind die RNA‑Polymerasen II, die aber auch unreife mRNA katalysieren, und die RNA‑Polymerasen III, die neben miRNA auch Transfer‑RNA katalysieren.
- Die miRNA-Codes befinden sich - wie die Gencodes - in der Regel auf dem DNA-Leitstrang, so dass dieser zur miRNA-Synthese abgelesen wird. Neuere Forschungen zeigen jedoch, dass bestimmte miRNA ihren Ursprung in der Transkription am Folgestrang haben können, der auch als komplementärer DNA-Strang oder Antisense-Strang bezeichnet wird. Dementsprechend werden diese miRNA auch Antisense-miRNA genannt.
- Die Vorstufe einer miRNA, die „primäre micro‑RNA“ (pri‑miRNA) hat nach der Transkription eine Struktur von ca. 500 bis 3.000 Nukleotiden.
- Die miRNA-Primärtranskripte weisen nach derzeitigem Stand der Forschungen jeweils eine Kappe als auch eine polyA‑Kette am Ende auf.
- Zunächst faltet sich das RNA-Molekül zu einer Schleife mit einem langen Ende (Haarnadelstruktur oder „hairpin loop“). Durch die Haarnadelstruktur entsteht eine gewundene, doppelsträngige miRNA (ds‑miRNA). Anschließend transportieren spezielle Proteine, beispielsweise Exportin 5, die ds‑miRNA vom Zellkern in das Zytoplasma, falls sie dort für die Genregulation vorgesehen ist.
- Jetzt wird die ds‑miRNA entwunden und mittels eines Dicer‑Enzyms in kurzkettige, ca. 20 bis 25 Nukleotide umfassende ds‑miRNA geschnitten. Anschließend wird die gekürzte ds‑miRNA von einem Argonautenprotein übernommen und in eine einzelsträngige miRNA transformiert.
- Danach übernimmt der im Argonautenprotein verbliebene genregulierende miRNA‑Strang mit Hilfe weiterer Proteine, die gemeinsam den RNA‑induced‑trancriptional-silencing complex (RITS-Komplex, das Pendant zum RISC der siRNA) bilden, seine regulatorischen Aufgaben an der mRNA, beispielsweise durch Unterbrechung des Translationsprozesses (→ Animation 9). Einer der Unterschiede zur siRNA betrifft die Anforderungen an die Spezifikation der Basensequenzen, denn miRNA-Basen müssen im Gegensatz zur siRNA mit der komplementären Ziel-mRNA nicht völlig identisch sein. Dadurch ist ein und dieselbe miRNA in der Lage, jeweils bis zu mehreren hundert Genen zu regulieren. Die zwischen miRNA und mRNA korrespondierenden Basenfolgen werden auch als Seed-Regionen (seed sequences) bezeichnet.
ANIMATION 9: MICRO-RNA-SYNTHESE UND GENREGULATION ALS RIBOSOMAL DROP-OFF
Animation 9 (ohne Audio-Kommentar): Synthese eines (aus Gründen einfacherer Darstellung verkürzten) Primärtranskripts pri‑miRNA durch eine RNA‑Polymerase II oder III an der DNA (DNA to RNA) im Zellkern, Auffaltung zur Haarnadelstruktur, Transport ins Zytoplasma, Processing der gewundenen, doppelsträngigen pri-miRNA zur einzelsträngigen miRNA ohne Darstellung der dafür notwendigen Enzyme, Verbindung mit einem RITS-Proteinkomplex (gelb) und Genregulation durch die Unterbrechung der Translation, indem das Ribosom gestoppt wird und sich anschließend von der mRNA löst (Ribosomal drop-off). Auf die Darstellung der vielen beteiligten Hilfsenzyme wurde verzichtet. Die komplementären Basensequenzen der in der Animation dargestellten miRNA stimmen nicht genau mit den Sequenzen der mRNA überein, was man an den vier nicht zusammenpassenden Basen in der Mitte erkennt. Die zwischen miRNA und mRNA passenden Basensequenzen werden als Seed-Regionen bezeichnet. Trotz der nicht vollständig passenden Basenfolgen nimmt die miRNA ihre modulierende Aufgabe wahr, eine 100%ige Übereinstimmung der Basensequenz zwischen mRNA und miRNA scheint nicht erforderlich. Offensichtlich sorgt das mit der miRNA verbundene Protein genau an der nicht übereinstimmenden Stelle für die Ausschaltung der nicht passenden Basensequenz. Die Zusammenarbeit mit verschiedenen Proteinkomplexen erlaubt es einer einzelnen Sorte miRNA, die Synthese mehrerer Typen von mRNA zu steuern, indem immer gerade die Basen vom Protein „angehoben“ werden, die einer Paarung im Wege stehen (siehe dazu auch Animation 10 und den Hinweis zur Spezifität von miRNA). (Quelle: YouTube/Rosetta Genomics, http://www.rosettagenomics.com)
Überblick: Verschiedene RNA-Mechanismen zur Regulierung eigener Gene
Mittlerweile sind zwei gegensätzliche RNA‑Wechselwirkungen bekannt. Sowohl RNA silencing (RNAi) als auch RNA activation (RNAa) werden durch verschiedene (Unter‑)Mechanismen repräsentiert, die keineswegs schon vollständig verstanden werden:
- Das RNA silencing (RNA-Stummschaltung) bzw. RNAi stellt eine Möglichkeit dar, die Proteinsynthese mittels kurzkettiger ncRNA zu unterbinden.
- Die RNA activation (RNA-Aktivierung) bzw. RNAa eröffnet die Möglichkeit, die Proteinsynthese mit kurzkettigen ncRNA zu forcieren.
In der wissenschaftlichen Literatur werden „RNA‑Interferenz“ und „RNA silencing“ gegenwärtig synonym verwendet, während die RNA‑Aktivierung als eigenständiger Prozess gilt. Die RNA‑Aktivierung wäre danach kein Interferenzmechanismus. Eine derart eng begrenzte Definition ist aber nicht sinnvoll, denn Begriffe wie „Wechselwirkung“ oder „Interferenz“ sagen nichts darüber, ob hemmend oder aktivierend beeinflusst wird. Die Gleichsetzung von RNA‑Interferenz mit RNA silencing könnte in den aktuellen Forschungsinitiativen begründet sein, die sich fast ausschließlich mit Letzterem beschäftigen, während über die RNA‑Aktivierung noch wenig bekannt ist.
Mechanismen des RNA silcencing mit miRNA
Es gibt Hinweise auf eine direkte Beeinflussung der Transkription durch miRNA (→ Nr. 1). Bei den meisten der bekannten Prozesse greifen miRNA jedoch überwiegend nach der mRNA‑Synthese oder während der Translation in die Proteinbiosynthese ein (→ Nr. 2):
- Genregulation mittels miRNA zur Verhinderung der Transkription
Bisher ist nur ein Prozess transkriptionaler Genregulation nachgewiesen, für eine zweite Variante gibt es erste Hinweise. Es wird daher vermutet, dass interferierende Eingriffe in die Transkription eher selten sind. In beiden Fällen kommt es durch DNA-Manipulationen erst gar nicht zur Synthese einer mRNA.
Beim dem nachgewiesenen prä-transkriptionalen Prozess wird die Transkription mit Hilfe des schon bekannten RITS‑Komplexes (RNA‑induced-transcriptional-silencing complex) reguliert. Der RITS‑Komplex manipuliert Histone an der DNA, so dass Enzyme keinen Zugang mehr zu diesen Stellen des Erbguts haben, und die Übersetzung des Codes in ein Peptid oder Protein von vorneherein verhindert wird.
Bei Untersuchungen von Lena Smirnova wurden miRNA-Bindungsstellen an der DNA gefunden, was auf die Möglichkeit einer unmittelbaren miRNA-Beteiligung am Transkriptionsgeschehen schließen lässt und damit eine Variante echter transkriptionaler Genregulation darstellte (Quelle: Lena Smirnova, Regulation und Funktion der microRNA während der neuronalen Entwicklung und Spezifizierung von Stammzellen, FU Berlin, Berlin 2008, http://www.diss.fu‑berlin.de/...). Auf diese Weise könnte eine miRNA ‑ vergleichbar mit einem Repressor‑Protein ‑ die Transkription verhindern oder unterbrechen.
- Genregulation durch Manipulationen der Translation
Das RNA silencing betrifft jedoch vor allem die Verhinderung oder Störung der Synthese von Peptiden oder Proteinen durch Eingriffe an der reifen mRNA kurz vor oder während der Translation. Derzeit wird von mindestens fünf Varianten ausgegangen, vier davon sind nachgewiesen. Es handelt es sich – je nach Prozessvariante oder Sichtweise – um eine prä‑translationale oder ko‑translationale bzw. translationale Repression durch miRNA.
Bei der ersten Variante blockieren miRNA die Initialisierungsfaktoren (eIFs) der Translation mit Hilfe von Argonauten-Proteinen durch eine Manipulation der Cap-Strukturen an der mRNA, so dass die ribosomale Untereinheit ihre Aktivitäten nicht beginnen kann (→ Animation 10) und die Translation damit vereitelt wird.
Bei der zweiten Variante erfolgt eine Manipulation der durch die Polyadenylierung entstandenen polyA-Kette am Ende der mRNA durch die miRNA mit Hilfe des RISC-Proteins, so dass ebenfalls keine Translation erfolgen kann.
Die dritte Prozessvariante ist die mRNA-Degradation, also die Zerstörung der mRNA mit Hilfe von miRNA und weiteren Enzymkomplexen und kann auch als eine Kombination von erster und zweiter Variante aufgefasst werden. Zunächst wird die polyA‑Kette entfernt, danach die Cap‑Strukturen und erst dann die restliche mRNA aufgebrochen (→ Animation 10) bzw. aufgelöst. Der Vorgang des mRNA-Bruchs wird auch als „cut of messengerRNA“ bezeichnet. Es handelt sich dabei um einen energetisch höchst aufwändigen Prozess, da die gesamte mRNA zerstört wird. Auch hier ist das Ergebnis die verhinderte Translation.
Eine vierte Interventionsmöglichkeit erfolgt nach der Initiationsphase, das heißt noch während der Synthese einer Aminosäurenkette. Es wurde festgestellt, dass miRNA auch mRNA reprimieren konnte, bei denen die Cap-Strukturen und die Polyadenylierung gar keine Rolle spielen. Es wird nun gemutmaßt, dass die miRNA entweder die Elongation während der Translation verlangsamt oder es zu einer vorzeitigen Termination der Translation ‑ auch „Ribosomal drop‑off“ genannt ‑ kommt (→ Animation 9 oben). Im ersten Fall hätte das eine reduzierte Proteinbiosyntheserate als Konsequenz, im zweiten Fall könnte diese sogar bis auf null sinken. Es zeigt, dass Genregulation sehr flexibel sein kann und nicht immer mit einem vollständigen Stopp der Proteinbiosynthese verbunden sein muss.
Eine fünfte Möglichkeit besteht im parallelen Abbau einer entstehenden Peptidkette (ko‑translationale Degradation) durch einen miRNA‑Protein‑Komplex, jedoch wurden die dafür nötigen Proteine noch nicht identifiziert (Quelle: Thermann, BIOspektrum Nr. 3/2008).
Die Animation 9 oben zeigt den Interferenzprozess stark vereinfacht. In der nachfolgenden Animation 10 werden zwei weitere translationale RNAi‑Mechanismen visualisiert: 1. Zerstörung der mRNA, auch mRNA‑Degradation bzw. cut of messengerRNA genannt, und 2. die Blockade der ribosomalen Untereinheit.
ANIMATION 10: MICRO-RNA-SYNTHESE UND ZWEI FORMEN DER GENREGULATION
Animation 10 (mit Audio-Kommentar auf Englisch): Die Animation zeigt verschiedene RNA‑Silencing‑Prozesse. Trotz ihrer Verschiedenheit verfügen alle Zellen, beispielsweise Haut-, Muskel und Knochenzellen, über einen identischen Gencode. Ein wichtiger Zelldifferenzierungsmechanismus wird mit kurzkettigen micro‑RNA (miRNA) gesteuert. Fehlende oder fehlerhafte miRNA können Genregulations- und Zellfunktionsstörungen als Folgen haben, im Beispiel werden Krebs- und Herz-Kreislauf-Erkrankungen (Cancer/Heart diseases) genannt. Natürlich betrifft das auch neurologisch-psychiatrische Erkrankungen, denn die Nerven- und Gliazellen des Zentralnervensystems sind ebenso auf eine exakte zelltypspezifische Genregulation angewiesen. Ein Blick in den Zellkern zeigt die schon beschriebene mehrstufige miRNA-Synthese durch Transkription und den nachfolgenden Transport in das Zytoplasma außerhalb des Kerns. Dort erfolgt eine Bearbeitung mit Hilfe mehrerer Proteinkomplexe (Dicer, Argonautenprotein AGO 2 etc.) so dass die miRNA genregulierende Funktionen übernehmen können. Die Animation zeigt mit der mRNA-Degradation und der mRNA-Blockade zwei Mechanismen translationalen RNA silencings. (Quelle: YouTube/Katharina Petsche)
RNA‑Interferenzen sind grundsätzlich auf allen Ebenen der Proteinbiosynthese denkbar, zum Beispiel auch während des mRNA-Processings oder durch Verhinderung des mRNA-Transports in das Zytoplasma, jedoch gibt es darüber noch keine gesicherten Erkenntnisse.
Da miRNA ‑ wie Peptide und Proteine ‑ ihren Ursprung als Codes auf der DNA haben, könnten sie sich sogar selbst regulieren. Naturgemäß hätten die Regulation die miRNA-Transkription oder das miRNA-Processing als Ziel, da eine Übersetzung der miRNA in Peptide nicht stattfindet und die Translation hier keine Rolle spielt.
Die RNA-Aktivierung (RNAa): Verschiedene Möglichkeiten zur Aktivierung von Genen mittels ncRNA
Bei der RNAa‑Genregulation erreicht die Zelle den gegenteiligen Effekt: Die Synthese bestimmter Peptide wird verstärkt. Auch hier sind miRNA in Zusammenarbeit mit Enzym- oder Proteinkomplexen beteiligt. Insgesamt werden mehrere Möglichkeiten diskutiert, die den oben beschriebenen RNA‑silencing‑Prozessen ähneln. Diese könnten u. a. durch eine Aktivierung der Transkription mittels Promotor-spezifischer miRNA und einem RITS‑Komplex oder durch eine Aktivierung der Translation mit Hilfe von miRNA und Argonautenproteinen charakterisiert sein.
Wie ist der hohe Aufwand translationaler Genregulation und die RNA-Aktivierung zu begründen?
Seit Entdeckung des RNA silencing wird über die Gründe dafür gerätselt: Warum führt die Zelle energetisch derart aufwändige Prozesse durch, in dem sie zunächst mRNA katalysiert und sie dann an ihren Aufgaben hindert oder sogar zerstört?
Ein naheliegender, trivialer Grund ist die Unterbrechung der Peptidproduktion: Die mRNA ist zwar nicht sehr stabil, würde ohne ein Regulativ dennoch für eine bestimmte Zeit unkontrolliert weiter Enzyme oder Proteine produzieren. Vor der Entdeckung der speziellen ncRNA-Regulationsmechanismen nahmen die meisten Wissenschaftler an, dass RNase‑Enzyme für die Deaktivierung der mRNA verantwortlich sind oder die mRNA aufgrund ihrer Instabilität irgendwann einmal von alleine aufhört, Proteine zu produzieren. Aber die Nutzung der RNAi ist hier die schlüssigere Erklärung.
Die Genregulation durch miRNA könnte der Zelle darüber hinaus eine bessere Feinsteuerung erlauben, da die Informationswege zum Zellkern sehr lang sind und so umgangen werden. Das bedeutet: Im Zellkern werden mRNA auf Vorrat produziert und im Zytoplasma dann bedarfsgerecht gezielt und kurzfristig ausgeschaltet.
Die RNA‑Aktivierung ist demgegenüber leichter nachzuvollziehen, denn mit der verstärkten Nutzung schon vorhandener mRNA spart die Zelle weitere aufwändige Transkriptionen. Das Argument der besseren Feinsteuerung gilt bei der RNA-Aktivierung gleichfalls.
Zirkuläre RNA als weitere Bausteine der RNA-Genregulation?
Anfang 2013 stellte sich heraus, dass Vertreter einer weiteren RNA-Klasse, die aus ringförmigen Molekülen (circular-RNA bzw. circRNA) besteht und Bindungsmöglichkeiten für miRNA aufweist, möglicherweise eine Rolle bei der Genregulierung spielen könnten (Quellen: Nature Journal bzw. Nature Reviews Genetics, doi:10.1038/nature11928, doi:10.1038/nature11993 und doi:10.1038/nrg3464, Februar + März 2013). Bekannt sind RNA-Ringe schon seit den 1970er Jahren, damals wurden sie jedoch als funktionslos betrachtet oder galten sogar als Zellschrott.
So hat die einzelsträngige circRNA mit der Bezeichnung Cdr1as bei einer Länge von etwa 1.500 Nukleotiden 70 Andockregionen für die miRNA miR-7, aber auch einige für die miRNA miR-671. Gerade in den Zellen von Säugetiergehirnen scheinen circRNA eine Bedeutung zu haben, denn sie kommen dort in einer auffällig großen Anzahl vor. Die circRNA Cdr1as wurde besonders häufig in bestimmten Nervenzellen gefunden, während es in Gliazellen keine Cdr1as gibt.
Durch ihre miRNA-Bindungsstellen könnten circRNA eine Modulation der Genregulation auf einer weiteren Ebene betreiben, indem sie miRNA regelrecht „aufsaugen“ und somit an ihren Aufgaben hindern. Von Forschern werden sie daher als „molekulare Schwämme“ bezeichnet. Weiter könnten circRNA auch Schutz- und Transportfunktionen für miRNA übernehmen. Denn miRNA, die mit einer circRNA verbunden sind, werden nicht so schnell abgebaut und können mit circRNA auch an andere Stellen innerhalb des Zellkörpers transportiert werden. Auch weitere Funktionen sind vorstellbar, vor allem im Zentralnervensystem (Quelle: Ringförmige RNA ist für Gehirnfunktion wichtig, Max-Dellbrück-Center für Molekulare Medizin in der Helmholtz-Gemeinschaft, Pressemitteilung vom 10.8.2017, https://mdc-berlin.de/news/...).
Mit einer dritten Ebene würde die Genregulation insgesamt noch komplexer und unübersichtlicher (→ Abbildung 7).
ABBILDUNG 7: DREI EBENEN DER GENREGULATION?
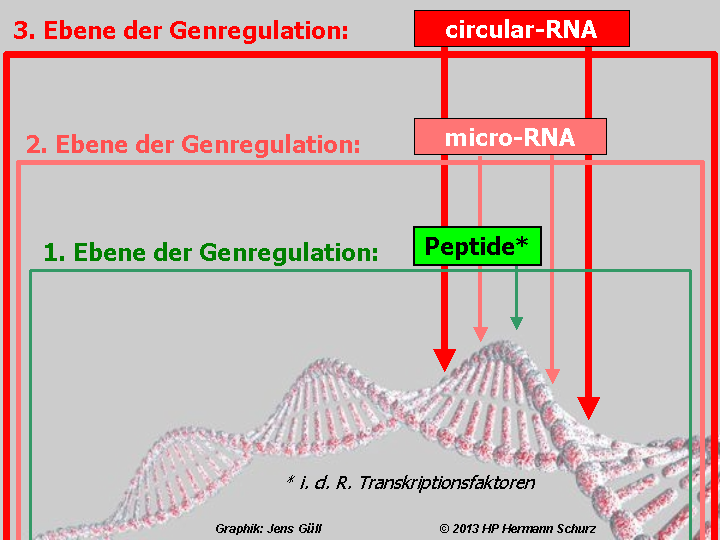
Abbildung 7: Die Proteinbiosynthese wird nach neueren Erkenntnissen wahrscheinlich von weiteren RNA-Molekülen moduliert, die Bindungsstellen für miRNA aufweisen und als zirkuläre RNA oder circular-RNA bzw. circRNA bezeichnet werden, da sie einen ringförmigen Aufbau haben. Dadurch könnte die Genregulation auf drei Ebenen und fünf grundsätzlichen Weisen ablaufen. Die schon seit langem bekannten Regulationspeptide (Transkriptionsfaktoren, Repressoren oder Histone bzw. einige andere Peptide, teilweise in Zusammenarbeit mit Hormonen) steuern die Genexpression direkt und autonom von den anderen Substanzen bzw. Ebenen (grüner Pfeil) oder ihre Synthese wird wiederum von miRNA reguliert (linker hellroter Pfeil), womit miRNA indirekt an den Genregulationsaktivitäten der Peptide beteiligt wären. Drittens wird die Synthese der Peptide durch miRNA gesteuert, die ihrerseits von circular-RNA reguliert werden (dunkelroter Pfeil ganz links). Auch miRNA regulieren unabhängig von der dritten Ebene entweder direkt (hellroter zweiter Pfeil von rechts), oder sie werden wiederum von circular-RNA gesteuert (dunkelroter Pfeil ganz rechts). Die Existenz dreier Modulationsebenen ist realistisch, wenngleich noch nicht endgültig belegt. Unberücksichtigt bleibt hier, dass miRNA-Moleküle ebenfalls die Transkription anderer ncRNA (circRNA oder auch andere miRNA) regulieren könnten.
Neueste Forschungen zeigen, dass bestimmte circRNA translatieren - demnach wie eine mRNA funktionieren. Da circRNA durch ihren ringförmigen Aufbau robuster sind als lineare mRNA, könnten circRNA auf diese Weise eine längere Zeit Peptide bzw. Proteine produzieren. Die Transformation linearer mRNA in circRNA, beispielsweise mit Hilfe von ncRNA-Molekülen, wäre ein wirkungsvoller RNAa-Mechanismus.
2.2.5 Übersicht: Die wichtigsten Klassen nicht-codierender RNA-Moleküle
Neben siRNA, miRNA und circRNA wurden in den letzten Jahrzehnten weitere nicht-codierende RNA identifiziert, die noch weitestgehend Gegenstände der Forschung sind und deren Funktionsspektrum noch nicht abschließend geklärt werden konnte. Einige sind nachweislich genregulierend, andere übernehmen Basisfunktionen bei der Proteinbiosynthese - wie die rRNA oder die tRNA.
„Housekeeping ncRNA“ ohne genregulierende Funktionen
Einige ncRNA sind für zelluläre Basisfunktionen unverzichtbar und ‑ wie die Transfer‑RNA (tRNA) oder die ribosomale RNA (rRNA) ‑ nicht an der Genregulation beteiligt. Sie werden wegen ihrer Aufgaben deshalb auch „Housekeeping ncRNA“ genannt:
- Ribosomale RNA (rRNA) haben eine Kettenlänge von mehr als 1.500 Nukleotiden und zählen damit zu den längsten ncRNA‑Molekülen. Sie bilden den RNA‑Teil der Ribosomen und ermöglichen diesen, an die mRNA anzudocken, damit die Translation in ein Peptid oder Protein vollzogen werden kann.
- Transfer-RNA (tRNA) sorgen dafür, dass während der Translation einzelne Aminosäuren zu Peptiden oder Proteinen verbunden werden. Sie haben eine Kettenlänge von knapp unter 80 bis 90 Nukleotiden.
- Small nuclear RNA (snRNA) haben eine Kettenlänge von 100 bis 300 Nukleotiden. Ihre Aufgaben erfüllen sie im Zellkern, daher auch die Bezeichnung. Sie sind am mRNA‑Splicing und ‑Processing beteiligt.
- Small nucleolar RNA (snoRNA) steuern gemeinsam mit snRNA ebenfalls das mRNA‑Processing im Zellkern, haben jedoch keine Funktionen beim Splicing. Sie sind tendenziell etwas kürzer als snRNA mit einer Kettenlänge zwischen 60 und 200 Nukleotiden.
- Primer-RNA leiten im Vorgriff auf die Kern- und Zellteilung die DNA‑Replikation ein.
Regulatorische RNA-Klassen
Den regulatorischen ncRNA ist gemein, dass sie weniger als 200 Nukleotide umfassen. Es werden folgende ncRNA‑Klassen unterschieden:
- Micro‑RNA (miRNA) übernehmen zentrale Aufgaben bei der zelleigenen Regulation der Proteinbiosynthese und bedienen sich zwei grundlegenden interferierenden Prozessen. Mit dem RNAi‑Prozess wird die Proteinsynthese unterdrückt oder gehemmt, mit dem RNAa‑Prozess wird die Proteinsynthese forciert. Die kurzen miRNA‑Moleküle weisen eine Länge zwischen 18 und 22 Nukleotiden auf. Sie werden als zelleigen bezeichnet, weil ihre Codes auf der Zell‑DNA gespeichert sind und von der Zelle selber bedarfsgerecht hergestellt (transkribiert) werden.
- Small interfering RNA (siRNA) bedienen sich des RNAi‑Prozesses und werden aus RNA gebildet, die von außen in die Zelle eingebracht wird, durch Viren oder experimentell. Ihre natürliche Funktion liegt daher in der Abwehr von Vireninfektionen. Small interfering RNA haben eine Kettenlänge zwischen 20 und 25 Nukleotiden.
- Piwi‑interaction RNA (piRNA) sind zwischen 26 und 31 Nukleotiden lang und haben spezielle Genregulationsfunktionen in den männlichen Geschlechtszellen bei der Spermatogenese. Sie wurden aber auch in weiblichen Geschlechtszellen (Ovar) gefunden, ihre Bedeutung dort ist jedoch noch nicht eindeutig geklärt. Ebenfalls ist nicht klar, ob sie darüber hinausgehende Funktionen außerhalb der Geschlechtszellen haben.
- Small cajal body‑specific RNA (scaRNA) scheinen speziell an der Regulierung spliceosomaler mRNA im Zellkern beteiligt zu sein. Ob andere Funktionen bestehen, ist noch nicht abschließend geklärt und Gegenstand aktueller Forschung.
- Circular-RNA (circRNA) mit einer Kettenlänge zwischen 100 und unter 200 Nukleotiden werden der ncRNA‑Klasse zugeordnet. Es gibt aber auch längerkettige circRNA mit bis zu 1.500 Nukleotiden, die zur lncRNA‑Klasse gehören (→ Funktionsbeschreibung für beide unten).
Nicht‑codierende RNA > 200 Nukleotide werden als long non‑coding RNA (lncRNA) bezeichnet. In den letzten Jahren wurden zwar immer mehr unterschiedliche lncRNA‑Moleküle identifiziert, sie sind derzeit dennoch die großen Unbekannten unter den RNA‑Klassen. Über ihre Funktionen gibt es nur rudimentäre Erkenntnisse, auch sie sind Gegenstände aktueller Forschung.
Langkettige lncRNA haben wahrscheinlich mannigfaltige biologische Funktionen, auch bei der Genregulation. Zwei spezielle lncRNA‑Klassen sollen hervorgehoben werden:
- Long intergenic RNA (lincRNA) spielen eine Rolle beim Aufbau von Proteinen und haben eine Länge von ca. 1.000 Nukleotiden.
- Die schon erwähnten genregulierenden Circular‑RNA (circRNA) ködern miRNA und beeinflussen damit deren Funktionen. Aber sie sollen dadurch auch in der Lage sein, Schutz- und Transportfunktionen für miRNA zu übernehmen. Circular‑RNA variieren bezüglich ihrer Länge, die zwischen 100 und etwa 1.500 Nukleotiden liegt. Zu den lncRNA gehören daher genregulierende circRNA mit einer Kettenlänge ab 200 Nukleotiden.
2.3 Mikro- und Makronährstoffe zur Durchführung der Zellprozesse▲
Alle vier Zellprozessbereiche (→ Abschnitt 2.1) benötigen eine substanzielle Grundlage für ihre Funktionsfähigkeit. Diese Grundlage bilden zusammen vor allem die Mikro- und Makronährstoffe.
Mikronährstoffe werden in der Regel mit Nahrung und Flüssigkeit in sehr geringen Mengen zugeführt und sind für die Durchführung fast aller Zellaktivitäten notwendig, beispielsweise...
- bei der Verwandlung von Peptiden in eine Vielzahl von Derivaten,
- bei der Tätigkeit von Nervenzellen,
- als Co-Enzyme für die Enzymtätigkeit oder
- dienen als Radikalfänger und schützen Zellen vor freien Radikalen und oxidativem Stress.
Zu den Mikronährstoffen zählen...
- Vitamine (→ Abschnitt 2.3.1),
- vitaminähnliche Substanzen (→ Abschnitt 2.3.2),
- die beiden n-3-Fettsäuren DHA und EPA,
- Mineralstoffe,
- Spurenelemente und
- Sekundärsubstanzen pflanzlichen Ursprungs.
Sekundäre Pflanzenstoffe zählen auch zu den Mikronährstoffen und bestehen aus Farb-, Bitter- und Gerbstoffen oder ätherischen Ölen. Sie werden hier jedoch nicht thematisiert. Diese Substanzen können bei der Abwehr verschiedener schädlicher Einflüsse auf Zellen, wie oxidative Prozesse oder Infekte, mitwirken. Sie sind im Zusammenhang mit den hier zu behandelnden Fragestellungen aber nicht von Bedeutung.
Auch Makronährstoffe werden mit der Nahrung aufgenommen, im Unterschied zu den Mikronährstoffen jedoch in größeren Mengen. Zu ihnen zählen...
- Kohlenhydrate,
- Peptide/Proteine bzw. die sie bildenden Aminosäuren und
- Fette.
Makronährstoffe lieferen Energie, sind Grundlage der Proteinbiosynthese, bei der die Bestandteile des Nahrungsproteins ‑ die Aminosäuren ‑ in körpereigene Proteine verwandelt werden (→ Abschnitt 2.2), und für den Aufbau der Zellmembranen mitverantwortlich.
Alle nachfolgenden Beschreibungen beziehen sich im Schwerpunkt auf die Aufgaben von Mikro- und Makronährstoffen bei der Proteinbiosynthese (Transkription, Translation) und im Nervensystem.
2.3.1 Vitamine
Vitamine sind organische Verbindungen, die dem Körper fast ausschließlich von außen zugeführt werden müssen, weil er sie entweder gar nicht oder nicht in ausreichender Menge herstellen kann.
Vitamin-A-Gruppe (insbesondere Retinol)
Um im Körper positiv wirksam zu sein, muss Retinol zuerst mit dem körpereigenen Retinol-Bindeprotein reagieren.
- Funktionen bei der Transkription:
Vitamine der A-Gruppe sind an der Genregulation beteiligt. Sie fungieren als Stopp-Markierungen und unterbinden die Transkription von Peptiden bzw. deren Codes, die gerade nicht benötigt werden.
- Bedeutung in den Gliazellen von Gehirn und Rückenmark:
Vitamine dieser Gruppe sind an der Myelinsynthese der Gliazellen im Nervensystem beteiligt ‑ sowohl bei den Oligodendrozyten im Gehirn und Rückenmark, als auch bei den Schwann'schen Gliazellen des peripheren Nervensystems.
Vitamin B1 (Thiamin)
Ähnlich wie das Retinol muss auch Thiamin mit einem Enzym verändert werden, bevor es aktiv werden kann.
Direkte Beteiligungen an Transkription und Translation sind nicht bekannt, jedoch ist Thiamin ‑ wie die B‑Vitamine B2, B3, B5, B6 und B12 ‑ an der Aufspaltung der Proteine zu Aminosäuren beteiligt. Erst dieser Vorgang ermöglicht die Proteinbiosynthese.
- Funktionale Prozesse der Nerven- und Gliazellen:
1. Thiamin ist Bestandteil der Nervenzellmembranen, somit eine Mitwirkung an der Reizübertragung sicher.
2. Die Synthese und Aktivität wichtiger Neurotransmitter ist von Thiamin abhängig, nachgewiesen für GABA, Serotonin, Acetylcholin und Adrenalin.
3. Thiamin schützt Cholin ‑ die Vorstufe von Acetylcholin bzw. Phosphatidylcholin ‑ in Nerven‑ und Gliazellen vor Abbau und Aufspaltung.
Vitamin B2 (Riboflavin)
Auch Riboflavin ist an der Spaltung des Nahrungsproteins in seine Aminosäurebausteine beteiligt.
- Funktionale Prozesse der Gliazellen:
Riboflavin ist gemeinsam mit Retinol aus der Vitamin‑A‑Gruppe beim Aufbau der Myelinschicht notwendig.
Vitamin B3 (Niacin)
Neben dem Abbau von Protein hat Niacin zahlreiche Funktionen.
Niacin ist ein Bestandteil des Glukosetoleranzfaktors, der Blutzuckerschwankungen glättet und somit auch einer Unterzuckerung nicht-diabetischen Ursprungs (Hypoglykämie‑Syndrom) entgegenwirkt, die vor allem für das Zentralnervensystem negative Folgen haben kann.
- Transkription:
Niacin ist für die Synthese der Histonproteine verantwortlich, die im Zellkern aktiv werden. Da Histone auch die Transkriptionsrate mitbestimmen, hat Niacin damit indirekt auch eine genregulative Bedeutung.
- Funktionale Prozesse in Nervenzellen:
Niacin verbindet sich mit mehr als 200 Enzymen, die auch im Zentralnervensystem eine Funktion übernehmen. So fördert Niacin auch die Synthese verschiedener Neurotransmitter.
Im Zusammenhang mit Niacin gibt es noch einen weiteren Aspekt, der neurologische Vorgänge betrifft: Eine Niacinunterversorgung kann nämlich einen negativen Einfluss auf die Serotoninsynthese haben.
Im Falle eines Niacinmangels muss der Körper Niacin aus der Aminosäure Tryptophan selber herstellen. Da Tryptophan wiederum für die Produktion von Serotonin wichtig ist, konkurrieren Serotonin- und Niacinproduktion miteinander um Tryptophan.
Dazu kommen besondere Umstände verschärfend hinzu. Die Niacinsynthese ist nicht besonders effektiv und verbraucht viel Tryptophan. Tryptophan wiederum ist in der Nahrung relativ zu den anderen Aminosäuren nur wenig enthalten, so dass die Gefahr eines Tryptophanmangels generell schon hoch ist. Zu allem Übel gehört Tryptophan zu den essentiellen Aminosäuren, die der Körper selber nicht herstellen kann. Der Körper ist auf ein ausreichende Tryptophanzufuhr angewiesen, denn ein Mangel kann nicht durch körpereigene Produktion ausgeglichen werden.
Vitamin B5 (Pantothensäure)
Pantothensäure wird als Coenzym A im Zellstoffwechsel aktiv, es finden sich hohe Konzentrationen im Gehirn. Auch das Coenzym A hilft bei der Spaltung von Proteinen in Aminosäuren.
- Funktionale Prozesse der Nerven- und Gliazellen:
1. Das Coenzym A hat Funktionen bei der Synthese des Neurotransmitters Acetylcholin.
2. Das Coenzym A wirkt ebenfalls an der Produktion von Taurin mit. Taurin hat mehrere Funktionen im Nervensystem, insbesondere im Bereich der Zellmembranstabilisierung. Auf die Menge des Acetylcholins hat Taurin einen positiven Einfluss.
Vitamin B6 (Pyridoxin)
Für Pyridoxin und dessen Derviate sind mehr als 200 enzymatische Reaktionen nachgewiesen. Seine allgemeine Bedeutung für das Nervensystem ist sehr hoch. Pyridoxin ist ein wichtiger Faktor im Stoffwechsel der Glukose, dem Energielieferanten des Gehirns.
Pyridoxin ist bei der Synthese nicht‑essentieller Aminosäuren notwendig. Auch bei der Aufspaltung des Nahrungsproteins in Aminosäuren übernimmt es wichtige Funktionen.
- Funktionale Prozesse der Nerven- und Gliazellen:
1. Vitamin B6 wirkt am Aufbau der Neurotransmitter Serotonin, Dopamin und Noradrenalin mit.
2. Wie die Pantothensäure ist Pyridoxin auch für die Synthese von Taurin zuständig.
Vitamin B7 (Biotin)
Auch Biotin übernimmt Funktionen im Glukosestoffwechsel und ist somit für Nervenzellfunktionen von grundlegender Bedeutung.
- Transkription und Translation:
1. Biotin ist, gemeinsam mit Niacin, für der Veränderung der Histone zuständig. Somit hat die Tätigkeit des Biotins indirekt Auswirkungen auf die Genregulation, da Histone die Transkriptionsrate beeinflussen.
2. Biotin ist an der Genexpression von mehr als 2.000 Genen direkt beteiligt, vermutlich auch in Zellen des zentralen Nervensystems.
Vitamin B9 (Folsäure)
Folsäure (Vitamin B9, seltener auch als Vitamin B11 bezeichnet) wird erst durch die enzymatische Umwandlung in Folat in der Leber biologisch aktiv. Wichtige Funktionen übernimmt Folat im Rahmen der DNA‑Replikation.
Folsäure ist auf die Verfügbarkeit von Cobalamin angewiesen (→ Vitamin B12‑Gruppe).
- Transkription:
Folat spielt eine wichtige Rolle beim Start der Transkription und damit bei der Synthese der mRNA.
- Funktionale Prozesse der Nerven- und Gliazellen:
Folat ist an der Synthese von Dopamin, Serotonin und Noradrenalin beteiligt.
Vitamin B12-Gruppe (Cobalamin)
Cobalamin steht für eine Gruppe von sechs Substanzen, die Kobalt enthalten. Adenylcobalamin ist die wichtigste von ihnen und als Coenzym B12 Teil mehrerer Enzyme. Das B‑Vitamin Folsäure arbeitet eng mit Cobalamin zusammen, so dass die Funktion der Folsäure bei Cobalaminmangel blockiert oder zumindest eingeschränkt ist.
Auch Cobalamin hilft bei der Aufspaltung von Protein in Aminosäuren.
- Transkription:
Cobalamin unterstützt die Nukleinsäurensynthese (DNA, RNA) und sorgt damit auch für einen reibungslosen Ablauf von Zellteilung und Transkription.
- Funktionale Prozesse von Nerven- und Gliazellen:
1. Cobalamin ist für Aufbau, Unterhalt und Regeneration von Gliazellmembranen unerlässlich. Ohne Cobalamin ist deren Myelinschicht von Abbau bedroht.
2. Für den Um‑ und Abbau von Neurotransmittern wird das Enzym S‑Adenosyl‑Methionin (SAMe) benötigt. SAMe kann nur mit Hilfe von Cobalamin synthetisiert werden.
3. Cholin, die Vorläufersubstanz des Neurotransmitters Acetylcholin und des Membranenbaustoffs Phosphatidylcholin, benötigt zur Synthese Cobalamin.
4. Bei Cobalamin‑Mangel steigen die Konzentrationen neurotoxisch wirkender Substanzen (nachgewiesen beispielsweise für Homocystein).
Vitamin C (Ascorbinsäure)
Ascorbinsäure ist hauptsächlich für den Aufbau des Kollagens zuständig, das in Bindegewebezellen von Bedeutung ist, im Gehirn beispielsweise für den Aufbau der Hirnhäute.
- Funktionale Prozesse von Nerven- und Gliazellen:
Die Synthese der Neurotransmitter Noradrenalin und Serotonin benötigt Vitamin C.
Vitamin-D-Gruppe (insbesondere Calciol bzw. Calcitriol)
In dieser Wirkstoffgruppe ist Calciol (auch als Vitamin D3 bezeichnet) am wichtigsten. Calciol ist ein nicht‑essentielles Vitamin, das der Körper bei Lichteinwirkung und UV‑B‑Strahlung in der Haut produziert.
Der strahlungsabhängige Calciol‑Anteil deckt 90% des Körperbedarfs ab, den Rest liefert die durchschnitlliche Ernährung (Quelle: P. Knuschke et al., UV‑abhängige Vitamin D Synthese ‑ Bilanzierung der Expositionszeit durch UV zur Produktion des optimalen Vitamin D3‑Bedarfs im menschlichen Körper, Ressortforschungsbericht zur kerntechnischen Sicherheit und zum Strahlenschutz, 2007 ‑ 2011, Technische Universität Dresden und Medizinische Fakultät Carl Gustav Carus, Klinik und Poliklinik für Dermatologie).
Häufig reicht die körpereigene Menge jedoch nicht aus, da sich die Bevölkerung im Schnitt zu wenig dem Sonnenlicht aussetzen will oder kann. Wahrscheinlich ist daher ein großer Teil der Bevölkerung mit Vitamin D unterversorgt.
Wirksam wird Calciol erst durch eine Modifikation mit dem Enzym 1‑alpha‑Hydroxylase zu Calcitriol.
- Transkription:
Im Bereich von Darm, Knochen und Niere ist die Beteiligung an der Transkription über den Vitamin-D-Rezeptor (VDR) bekannt. Das ist auch im Bereich des Gehirns möglich, dazu gibt es aber derzeit noch keine Nachweise oder Studien.
- Funktionale Prozesse von Nerven- und Gliazellen:
1. Vitamin D beeinflusst die Reizleitgeschwindigkeit motorischer Nervenzellen.
2. Calcitriol ist an der Synthese von Wachstumsfaktoren im Gehirn beteiligt. Das betrifft sowohl Nerven- als auch Gliazellen. Dadurch steuert es auch die Entwicklung des Zentralnervensystems im Embryonalstadium.
3. Studien lassen darauf schließen, dass Vitamin D auch an der Neurotransmitter-Synthese seinen Anteil hat. Die genauen Ursache-Wirkungs-Beziehungen sind jedoch noch unbekannt.
4. Im gesamten Gehirn befinden sich Calcitriol‑Rezeptoren: im präfrontalen Cortex, Thalamus und Hippocampus, außerdem im Kleinhirn. Deren Bedeutung ist noch weitgehend unbekannt.
5. Untersuchungen deuten auf einen Zusammenhang zwischen neurologischen und psychiatrischen Erkrankungen und Vitamin‑D‑Mangel hin, insbesondere bei Morbus Parkinson, Multipler Sklerose, Depressionen und Demenz. Die genauen Ursachen und Wirkungen sind nicht bekannt, ergeben sich eventuell aus den oben geschilderten Zusammenhängen.
Vitamin-E-Gruppe (Tocopherole und Tocotrienole)
Insgesamt zählen 16 Substanzen zur Gruppe der E‑Vitamine, je vier davon gehören zu den Tocopherolen bzw. den Tocotrienolen (alpha-, beta-, gamma‑ und delta‑Tocopherole bzw. ‑Tocotrienole). Das bekannteste E‑Vitamin ist das alpha-Tocopherol.
- Transkription und Translation:
Einen Einfluss von alpha-Tocopherol auf die Genexpression während der Transkription belegen Studien belegt, allerdings noch nicht für die das Nervensystem betreffenden Gene. Eine Untersuchung in den USA führte zur Feststellung, dass Tocotrienole einen Einfluss auf die Genexpression bei der Synthese von Cholesterin haben. Es besteht daher eine gewisse Wahrscheinlichkeit, dass sie auch Aufgaben während der Proteinbiosynthese im Nervensystem erfüllen.
Die Hauptaufgabe von E‑Vitaminen ist allerdings der Schutz innerer und äußerer Zellmembranen vor freien Radikalen und reaktiven Sauerstoff‑Spezies (ROS). Der ständige, ungeschützte Beschuss von freien Radikalen und ROS kann zu Zellerkrankungen und schließlich zum Zelltod führen. Aber auch weitere Vitamine haben ähnliche Zellschutzfunktionen. Von derartigen Aktivitäten profitiert natürlich vor allem das Nervensystem.
Vitamin-K-Gruppe (Phyllochinon bzw. Menachinon)
Die beiden K‑Vitamine sind hauptsächlich für die Blutgerinnung und den Aufbau des Knochensystems zuständig, hier über eine Beeinflussung der Transkription zweier Gene. Die Hälfte des Bedarfs an Vitamin K produziert der Körper selbst.
Aufgrund der Ergebnisse aktueller Forschungen wird vermutet, dass Vitamin K spezifische Proteine im Gehirn aktiviert, die Neuronen myelinisieren, und damit an der Qualität der Erregungsleitung beteiligt sein soll.
Ein weiterer Zusammenhang könnte für den Zellmembranstoffwechsel im Zentralnervensystem bestehen, da Vitamin K für die Synthese von Sphingolipiden verantwortlich sein soll.
2.3.2 Vitaminähnliche Substanzen (Vitaminoide)
Vitaminähnliche Substanzen (auch als Vitaminoide bzw. „Pseudo-Vitamine“ bezeichnet) sind organische Mikronährstoffe, die sowohl Bestandteile der Nahrung sind als auch vom Körper ausreichend synthetisiert werden. Im Unterschied zu Vitaminen wäre eine zusätzliche Zufuhr also nicht notwendig.
Einige Pseudo‑Vitamine wurden aufgrund fehlenden Wissens über den tatsächlichen Bedarf zunächst als Vitamine eingestuft, später wurde dieser Status wieder aberkannt oder er ist umstritten. Hierzu noch einige Anmerkungen:
- Auch eine Aufnahme vitaminähnlicher Substanzen über die Nahrung ist sinnvoll, da eine vollständige Eigensynthese Ressourcen bindet oder den Körper in anderer Weise belastet. Für deren Synthese ist darüber hinaus ein gesunder Organismus notwendig. In Phasen von Krankheit oder bei anderweitigen Belastungen, beispielsweise erhöhtem psychischen Stress und daraus resultierendem erhöhten Bedarf, kann ein Pseudo-Vitamin zu einem „echten“ Vitamin mit der Notwendigkeit werden, den Bedarf von außen zu decken.
- Ebenfalls ändern sich manchmal die Ansichten, wie viel von einer Substanz tatsächlich benötigt wird (→ Phostphatidylcholin/Cholin).
- Es ist zu hinterfragen, warum der Körper eine Substanz selber herstellt, die bei einer durchschnittlichen Ernährungssituation dem Körper zugeführt wird. Das liegt entweder daran, dass der Körper an eine bestimmte Menge durch Nahrungsaufnahme gewohnt ist, welche aber nicht ausreicht oder dass es häufiger zu Schwankungen in der Nahrungsaufnahme kommt. In beiden Fällen würde es sich gemäß der Definition aber unbedingt um ein Vitamin handeln.
Aus diesen Gründen ist es ein Trugschluss zu glauben, es käme bei „Pseudo‑Vitaminen“ überhaupt nicht auf eine Zufuhr durch die Nahrung an.
Phosphatidylcholin/Cholin
Vor der Aberkennung als Vitamin gab es für Phosphatidylcholin die Bezeichnung B4, die heute zum Teil noch verwendet wird. Denn Studienergebnisse deuten auf einen täglichen Aufnahmebedarf von drei bis vier Gramm. Viele Wissenschaftler sind daher der Meinung, dass eine zusätzliche Aufnahme notwendig ist. In diesem Falle müsste Phosphatidylcholin den Vitaminstatus wieder erhalten.
Über die Nahrung wird die Substanz so gut wie ausschließlich als Phosphatidylcholin aufgenommen, in der Leber resorbiert und steht dann als Cholin zur Verfügung. Zusätzlich wird körpereigenes Cholin in Leber und Nieren synthetisiert. Dafür müssen genügend Aminosäuren, insbesondere Lysin und Methionin, zur Verfügung stehen. Cholin übernimmt als Gallensäurebestandteil die Aufgabe der Emulgation von Fetten und ist damit an der Fettverdauung beteiligt.
Interessant sind hier aber vor allem die Bedeutung von Cholin für das Nervensystem. Cholin durchdringt die Blut‑Hirn‑Schranke und wird in den Hirnzellen entweder wieder zu Phosphatidylcholin rücksynthetisiert oder dient als Grundsubstanz der Herstellung von Botenstoffen.
- Funktionale Prozesse von Nerven- und Gliazellen:
1. Cholin ist die Grundlage der Synthese von Acetylcholin, einer der am häufigsten verwendeten Botenstoffe. Acetylcholin ist der wichtigste Neurotransmitter des peripheren Nervensystems, aber auch im zentralen Nervensystem hat es wichtige Funktionen, die noch nicht bis ins letzte Detail geklärt sind. So kontrolliert Acetylcholin Herzschlag und Blutdruck durch Aktivitäten im Stammhirn. Weiter ist es für Wahrnehmung, Konzentrationsfähigkeit, Entscheidungsfähigkeit, Lernvorgänge und das Erinnerungsvermögen zuständig. Nervenzellen, die Acetylcholin verwenden, sind bei einer Cholinunterversorgung vom Absterben bedroht.
2. Cholin wird für Aufbau und Erhalt der Zellmembranen in Hirnzellen wieder zu Phosphatidylcholin rücksynthetisiert, also der Form, in der es schon über die Nahrung zugeführt wurde. Phosphatidylcholin ist zu 50% Bestandteil der äußeren Zellmembranenschicht. Neben seiner Beteiligung am Membranaufbau sorgt es dafür, dass Cholesterin seine Viskosität als Membranbestandteil behält und nicht verkrustet, denn auch das würde den Zelltod bedeuten.
Bestimmte Eigenschaften von Cholin haben einen indirekten Einfluss auf die Funktionsfähigkeit des Nervensystems. So besteht ein Zusammenhang zwischen der Menge des für das Nervensystem schädlichen Schlackenstoffs Homocystein und der Cholinversorgung, da Cholin den Homocystein‑Spiegel senkt.
Inositol (Myo-Inositol)
Inositol hatte früher einen Status als B‑Vitamin, der heute umstritten ist. Myo‑Inositol ist die für den menschlichen Organismus verwertbare Form, woraus der Körper dann verschiedene Verbindungen synthetisiert, beispielsweise Phosphatidylinositol. Die Konzentration von Myo‑Inositol ist im Gehirn besonders hoch. Andere Formen, beispielsweise Scyllo-Inositol, sind auch im Gehirn in geringerer Konzentration vorhanden (etwa 10% des Myo-Inositol-Anteils).
- Transkription und Translation:
In Pflanzen- und Hefezellen ist die Beteiligung von Inositol an der Genexpression belegt. Für den menschlichen Organismus sind noch keine vergleichbaren Funktionen nachgewiesen.
- Funktionale Prozesse von Nerven- und Gliazellen:
1. Phosphatidylinositol ist ein Bestandteil der Zellmembranen, wenn auch in wesentlich geringerem Umfang als Phosphatidylcholin. Phosphatidylinositol ist ausschließlich in der inneren Zellmembranschicht lokalisiert und für die Membranfunktionen von grundlegender Bedeutung.
2. Inositol1,4,5-triphosphat (IP3) ist an der Reizweiterleitung von äußeren Signalen ins Zellinnere beteiligt, indem es an spezifische IP3-Rezeptoren innerer Zellmembranen andockt.
3. Im Nervensystem ist es an der Reizverarbeitung beteiligt, da es Teil des Enzyms Na1/K1-ATPase ist und für eine reibungslose Impulsübertragung sorgt.
2.3.3 Mineralstoffe (Elektrolyte)
Mineralstoffe bzw. Elektrolyte sind – im Gegensatz zu Vitaminen – anorganische Mikronährstoffe. Auch Mineralstoffe erhält der Körper über die Nahrung.
Alle sechs Mineralstoffe übernehmen im Nervensystems wichtige Funktionen: Calcium, Phosphor, Chlorid, Kalium, Natrium, und Magnesium.
Calcium
Calcium ist der am häufigsten im Körper vorkommende Mineralstoff, ein durchschnittlich schwerer männlicher Erwachsener enthält ca. 1 kg Calcium. Es findet sich zu 99% in Knochen und Zähnen. Der Rest von einem Prozent ist hauptsächlich für das Nervensystem bedeutend.
- Transkription:
Calcium ist zusammen mit dem cAMP-Reaktions-Element (CRE) an der Genexpression im Nervensystem beteiligt. Calcium sorgt für die Umwandlung des im Zellkern inaktiven CRE zum aktiven CREB (cAMP‑Reaktions‑Element‑Bindungsprotein), welches die Transkription der Gene neuroaktiver Katecholamine (Adrenalin, Noradrenalin und Dopamin), Neuropeptide und Neurotrophine einleitet.
- Funktionale Prozesse von Nervenzellen:
Calcium ist an der neuronalen Reizweiterleitung beteiligt. Wenn ein Impuls die Synapse erreicht, strömen Calcium-Ionen durch Kanäle in die Nervenzelle. Die genauen Gründe und Auswirkungen dieses Vorgangs sind immer noch nicht vollständig geklärt.
Phosphor
Phosphor ist mit seinen Verbindungen und ca. 0,7 kg das zweithäufigste Element in unserem Körper nach Calcium. Phosphor ist Bestandteil vieler Enzyme.
Es ist in fast jedem Lebensmittel enthalten, so dass Mangelversorgungen nicht zu erwarten sind. Vor allem bei ungesunder Ernährungsweise (viel Fleisch, raffinierter Zucker und phosphathaltige Limonaden) erhält der Körper eher ein Überangebot an Phosphor. Phosphor befindet sich zu 90% hauptsächlich in Knochen und Zähnen.
- Transkription und Translation:
Phosphate sind als Bestandteile von DNA und RNA grundlegend für die Proteinsynthese im gesamten Körper ‑ und damit auch im Nervensystem.
- Funktionale Prozesse von Nerven- und Gliazellen:
1. Als Bestandteil der Membranlipide, insbesondere bei den Myelin-Membranen der Gliazellen, ist Phosphor wichtig für das Nervensystem.
2. Phosphat verbindet sich mit Cholin und Inositol zu Phosphatidylcholin bzw. Phosphatidylinositol und wird in diesen Formen in den Hüllen der Nerven- und Gliazellen aktiv. Weitere Verbindungen sind Phosphatidylserin, Phosphatidylethanolamin und Phosphatidylglycerin, die im Gehirn ähnliche Funktionen haben.
Chlorid
Chlorid kommt nur in Verbindung mit anderen Mineralstoffen und Spurenelementen vor, wobei das Natrium den größten Anteil daran hat. Chlorid und Natrium arbeiten im Nervensystem eng zusammen. Die Informationen zum Natrium gelten daher auch für Chlorid.
Kalium und Natrium
Kalium steht bezüglich seiner Konzentration im menschlichen Körper im Vergleich mit anderen Mineralstoffen an vierter Stelle (ca. 100 bis 150 Gramm). Kalium verbindet sich mit zahlreichen Enzymen und übernimmt dabei viele Funktionen. In der Regel steht genügend Kalium in der Nahrung zur Verfügung.
Natrium ist im Organismus etwas weniger vorhanden als Kalium. Natrium wird überwiegend über das Salz in der Nahrung aufgenommen, in der Regel entsteht beim Menschen kein Natriummangel.
Kalium und Natrium sind nicht direkt an der Proteinbiosynthese beteiligt. Natrium hilft jedoch ‑ wie einige B‑Vitamine ‑ bei der Resorbierung von Aminosäuren aus der eiweißhaltigen Nahrung, einer Voraussetzung für die Proteinbiosynthese.
- Funktionale Prozesse von Nervenzellen:
1. Kalium und Natrium bewerkstelligen als Gegenspieler gemeinsam die Nervenreizweiterleitung. Dazu strömen kurzfristig Natriumionen durch die Membran in die Nervenzelle, danach strömen Kaliumionen aus der Nervenzelle. Diese kurzfristige Ionenverschiebung stellt den Impuls dar. Dazu muss natürlich auch ein Zustand in Ruhe herrschen, der durch die Natrium-Kalium-Pumpe erzielt wird, wobei ständig Natriumionen aus der Zelle herausgepumpt und Kaliumionen hineingepumt werden.
2. Kalium und Natrium sind ebenfalls an der Nervenreizübertragung zwischen den Nervenzellen beteiligt.
Magnesium
Magnesium ist in einer relativ niedrigen Konzentration von nur ca. 25 Gramm im menschlichen Körper enthalten, davon etwa zur Hälfte im Knochengewebe. Mehr als 300 Enzyme benötigen Magnesium als Co‑Faktor, wovon vor allem der Energiestoffwechsel und die Proteinsynthese betroffen sind. Magnesium regelt u. a. die Durchlässigkeit der Zellmembranen und hat im Nervensystem verschiedene Funktionen.
- Transkription und Translation:
1. Magnesium ist Bestandteil der RNA-Polymerase, die im Verlauf der Transkription RNA-Nukleotide zu Basenketten verknüpft.
2. Magnesium spielt bei der Translation eine wichtige Rolle. Die beiden Teile der Ribosomen müssen sich vor Beginn des Translationsprozesses vereinen, was nur mit Hilfe von Magnesium möglich ist. Magnesium ist ebenfalls als Co-Faktor an der Beladung der tRNA mit Aminosäuren beteiligt, ohne die eine Translation überhaupt nicht möglich wäre.
3. Magnesium bildet die Sekundärstruktur von Nukleinsäuren.
- Funktionale Prozesse von Nerven- und Gliazellen:
1. Magnesium hat bei der Reizweiterleitung eine hemmende Funktion und damit eine beruhigende Wirkung auf übermäßig aktive Nervenzellen. An den präsynaptischen Endkolben der Nervenleitungen vermindert Magnesium die Transmitterausschüttung.
2. Magnesium ist für die Funktion des N-Methyl-D-Aspartat-Rezeptors zuständig, der langfristige Veränderungen der Nervenreizübertragung steuert.
3. Beispiele für die Funktionen des Magnesiums als Co-Faktor zahlreicher Vorgänge im Nervensystem sind die Enzyme Serinracemase, Calcium-Calmodulin-abhängige Proteinkinase II und die Proteinkinase C, welche verschiedene Prozesse an den Synapsen der Nervenzellen und in Gliazellen überwachen.
2.3.4 Spurenelemente
Spurenelemente unterscheiden sich von den anorganischen Mineralstoffen nur durch ihren wesentlich geringeren Bedarf. Das drückt sich in der Konzentration pro kg Körpergewicht aus, die hier weniger als 50 mg beträgt.
Bor
Es gibt verschiedene Studien und Anwendungsbeobachtungen, die einen Einfluss von Bor auf verschiedene kongnitive Leistungen nahelegen. Nachweise über kausale Zusammenhänge mit neurologischen Prozessen konnten noch nicht erbracht werden.
Chrom
Das Funktionsspektrum von Chrom ist noch nicht restlos geklärt. Chrom wird vor allem mit dem Glukosestoffwechsel in Verbindung gebracht, da es ‑ wie auch das Vitamin B3 ‑ als Bestandteil des Glukosetoleranzfaktors den Kurvenverlauf des Zuckers im Blut glättet.
- Transkription:
Die Konzentration in den Zellkernen ist auffällig hoch, so dass Chrom mit der Zellteilung oder Transkription in Verbindung stehen könnte. Näheres ist darüber noch nicht bekannt.
- Allgemeine Prozesse in Nerven- und Gliazellen:
Chrom sorgt mit dafür, dass Glukose in Zellen transportiert wird. Das ist vor allem für Neuronen von hoher Bedeutung, da deren Energieversorgung ausschließlich mit Glukose betrieben wird.
Eisen
Die bekanntesten Funktionen von Eisen sind der Transport und die Speicherung von Sauerstoff oder die Beteiligung am Energiestoffwechsel. Beides hat Auswirkungen auf das Nervensystem, da gerade hier Energie- und Sauerstoffbedarfe hoch sind.
Ebenfalls sinkt bei Eisenmangel der Spiegel des Schilddrüsenhormons Thyroxin, verbunden mit einer Verminderung des Stoffwechsel-Grundumsatzes und erheblichen psychischen Befindlichkeitsstörungen.
Eisen hat auch direkte Aufgaben im Zentralnervensystem. Teilweise sind die Zusammenhänge nicht geklärt, jedoch kann aufgrund der Untersuchungen von Eisenmangelzuständen auf dessen Mitwirkung geschlossen werden.
- Funktionale Prozesse:
Eisenmangel führt zu einer Unterversorgung mit den Neurotransmittern Dopamin, Serotonin, GABA und Acetylcholin.
- Weitere Besonderheiten im Zusammenhang mit dem zentralen Nervensystem:
Zum Krankheitsbild des Eisenmangel-Syndroms ohne Anämie gehört auch die Depression. Bei einem Eisenmangel-Syndrom ohne Anämie liegt kein messbarer oder nur geringer Eisenmangel vor, Blutbildung und Sauerstoffversorgung sind nicht eingeschränkt. Dennoch werden depressive Symptome nach Einnahme von Eisenpräparaten oder Eiseninfusionen gemildert. Das könnte mit den negativen Folgen einer Unterversorgung mit den o. g. Botenstoffen oder Energieversorgungsproblemen zusammenhängen. Eine plausible Erklärung wäre, dass das zur Verfügung stehende Eisen zunächst einmal die überlebenswichtige Sauerstoff- und Energieversorgung sicherstellt, daher könnten schon kleinere Eisenmängel untergeordnete Funktionen stören.
Jod
Die Bildung der Schilddrüsenhormone Thyroxin und Triiodthyronin ist nur mit Jod möglich und hier liegt die einzige Aufgabe des Spurenelements: Thyroxin enthält vier Jodatome, Triiodthyronin drei Jodatome. Beide Hormone werden schon im Mutterleib dringend benötigt, da sie beim Fötus u. a. den Aufbau von Gehirn und Rückenmark steuern. Ihre Aufgaben setzen sie nach der Geburt fort.
- Transkription:
Beide Schilddrüsenhormone regulieren die Genexpression in der Transkriptionsphase. Dadurch steuern sie die o. g. Entwicklung von Gehirn und Rückenmark bis ins Kleinkindalter.
- Funktionale Prozesse von Nerven- und Gliazellen:
Jodhaltige Schilddrüsenhormone wirken aktivierend u. a. auf das Gehirn, da sie den Grundumsatz des Organismus regeln. Niedrige Konzentrationen von Thyroxin und Triiodthyronin verlangsamen den Stoffwechsel und können zu einer depressiven Symptomatik führen.
Kobalt
Seine Bedeutung erhält Kobalt durch seine Eigenschaft als Bestandteil von Vitamin B12. Daher gelten die dort beschriebenen Zusammenhänge auch für Kobalt.
Kupfer
Kupfer ist am Energiestoffwechsel beteiligt, hat seinen Anteil an der Blutbildung und am Aufbau des Bindegewebes (Kollagen- und Elastinbildung).
- Funktionale Prozesse von Nerven- und Gliazellen:
1. Kupfer wirkt durch seine Beteiligung an der Bildung von Adrenalin und Noradrenalin indirekt auf das Gehirn. Sie entstehen zwar vorwiegend in der Nebenniere, aber auch im peripheren und zentralen Nervensystem. Die im Gehirn benötigte Menge wird direkt dort synthetisiert, da beide Substanzen an der Blut-Hirn-Schranke nicht vorbeikommen. Adrenalinrezeptoren wurden vorwiegend in den der Formatio reticularis zugehörigen Nervenzellen des Gehirns gefunden, ihre Funktionen sind aber bis heute nicht geklärt.
2. Dopamin benötigt für seine Umwandlung in Noradrenalin ein kupferhaltiges Enzym.
3. Kupfer ist in den Gliazellen an der Myelin‑Synthese beteiligt und hält als Bestandteil eines Enzyms die Myelinschicht feucht.
Mangan
Mangan gehört zu den essentiellen Spurenelementen und reagiert mit mehr als 50 Enzymen. Mangan arbeitet mit Vitamin B1 zusammen, das ‑ wie oben beschrieben ‑ einige Funktionen im Nervensystem erfüllt. Mangan findet sich in Ribonukleotidreduktasen und ist dadurch bei der DNA-Synthese beteiligt.
- Funktionale Prozesse von Nerven- und Gliazellen:
1. Mangan synthetisiert ‑ zusammen mit anderen Substanzen ‑ den Neurotransmitter Dopamin.
2. Das Spurenelement spielt in den Gliazellen des Gehirns als Enzymbestandteil eine Rolle.
Molybdän
Viele Zellprozesse benötigen Molybdän, obwohl der Körper im Schnitt nur 10 mg davon enthält. Es spielt als Co‑Faktor in der Zusammenarbeit mit vielen Proteine eine Rolle, beispielsweise im Energiestoffwechsel oder beim Aufbau wichtiger bzw. Abbau schädlicher Substanzen. Von daher ist es im Nervensystem oder bei der Proteinbiosynthese mit Sicherheit indirekt von Bedeutung. Für eine unmittelbare Beteiligung an der Genexpression bzw. neuronalen Prozessen gibt es derzeit keine Anhaltspunkte.
Rubidium
Rubidium zählt zu den unbekannteren Spurenelementen, dessen Bedeutungen für das Nervensystem sich nur langsam klären. Im Gehirn kommt es in sehr kleinen Mengen vor. Die Einschätzung des Rubidiumbedarfs ist durch diese vielen Unwägbarkeiten schwierig. Derzeit wird von einem täglichen Bedarf von 100 Mikrogramm ausgegangen, wobei die mit Nahrung aufgenommene Menge täglich ein Vielfaches davon beträgt.
- Funktionale Prozesse von Nerven- und Gliazellen:
Es wird vermutet, dass Rubidium an der Nervenreizübertragung durch die Regelung von Botenstoffkonzentrationen beteiligt ist.
Selen
Selen ist Bestandteil vieler Enzyme und Proteine. Untersuchungen haben ergeben, dass die Selenversorgung in Deutschland zwar an der unteren Grenze der empfohlenen Menge liegt, dennoch nicht von einer Mangelversorgung ausgegangen wird.
Aufgrund seiner antioxidativen Wirkung profitiert das Nervensystem von Selen. Selen schützt dadurch auch Nerven- und Gliazellen. Selen bewahrt das Nervensystem darüber hinaus vor zu hohen Konzentrationen des Nervengifts Glutaminsäure.
- Funktionale Prozesse von Nerven- und Gliazellen:
Selenhaltige Enzyme sind an der Aktivierung und Deaktivierung von Adrenalin und Noradrenalin beteiligt.
Zink
Zink findet sich als Co‑Faktor vieler Enzyme in bestimmten Hirnregionen in höherer Konzentration.
- Transkription:
1. Zinkhaltige Enzyme und Proteine haben bei der Transkription zwei wichtige Funktionen. Zink ist zum einen Bestandteil der Zinkfingerproteine. Diese Proteingruppe zählt zu den Transkriptionsfaktoren, die für die Initiation der RNA‑Polymerasen zuständig sind.
2. Darüber hinaus ist Zink Bestandteil von Polymerasen, der Thymidin‑Kinase, der reversen Transkriptase und der Ribonuklease und damit unentbehrlich für die Nukleinsäurensynthese.
3. Da Zink auch für die Synthese des Retinol‑Bindeproteins benötigt wird, sind die Funktionen des Retinols von Zink abhängig. Retinol ist im Rahmen der Transkription ebenfalls an der Genregulation beteiligt. Damit erhöht sich die Bedeutung von Zink für die Transkription.
- Funktionale Prozesse von Nerven- und Gliazellen:
Zink wirkt verstärkend auf den inhibitorischen Neurotransmitter Glycin.
2.3.5 Essentielle Aminosäuren
Peptide und Proteine bestehen aus einzelnen Aminosäuren, die jeweils in einer Kette miteinander verbunden sind. Damit gehören Aminosäuren zu den Grundbausteinen des Lebens. Es gibt viele unterschiedliche Aminosäuren, aber nur 20 Typen spielen beim Aufbau und Unterhalt irdischer Lebensformen als proteinogene Aminosäuren eine Rolle. Bestimmte Aminosäuren haben im Nervensystem eine im Vergleich höhere Bedeutung, da sie an der Synthese von Peptiden und Proteinen mitwirken, die dort besonders wichtig sind.
Acht Aminosäuretypen müssen unbedingt über die Nahrung aufgenommen werden, denn Zellen können sie nicht selbst herstellen, sie sind essentiell. Die restlichen zwölf Aminosäuren werden in der Regel im Körper in ausreichender Menge produziert und als nicht‑essentiell bezeichnet (→ Abschnitt 2.3.6).
Verzweigtkettige Aminosäuren (BCAAs): Isoleucin, Leucin und Valin
BCAA ist die Abkürzung für „Branched‑chain amino acid“. Zu den BCAAs gehören die essentiellen Aminosäuren Isoleucin, Leucin und Valin. BCAAs sind an grundlegenden Lebensprozessen beteiligt, die auch für das Gehirn wichtig sind: Isoleucin garantiert die Sauerstoffversorgung durch Bildung des roten Blutfarbstoffs Hämoglobin und ist an der Blutzuckerstabilisierung beteiligt. Leucin und Valin werden für die Synthese von Insulin und Somatrophin gebraucht, Leucin für die Steuerung des Cortisolspiegels.
Isoleucin, Leucin und Valin haben aber auch im Zentralnervensystem eine besondere Bedeutung aufgrund ihrer Beteiligung an der Synthese von Neurotransmittern und Hormonen, beispielsweise Acetylcholin, Adrenalin, Dopamin, Glutamat, Glutamin, Histamin, Noradrenalin und Serotonin. Sie sind auch wichtig für die Synthesen von GABA (Gamma-Aminobuttersäure) und Melatonin, deren Vorstufen Glutamat bzw. Serotonin sind.
Lysin
Lysin ist eher von allgemeiner Bedeutung, es ist an der Synthese zahlreicher Peptide beteiligt.
In bestimmten für Affekte zuständigen Bereichen des Gehirns gibt es 5‑HT4‑Rezeptoren, die bei Stress eine aktivierende Rolle spielen und an denen Lysin als Antagonist wirken kann: Lysin besetzt den Rezeptor passiv, das heißt ohne eine eigene biochemische Wirkung zu entfalten und verhindert damit aber gleichzeitig, dass andere aktive Signalstoffe an 5‑HT4 andocken.
Methionin
Methionin ist für die Synthese von Phosphatidylcholin (→ Abschnitt 2.3.2) maßgeblich, das eine hohe Bedeutung für den Aufbau von Zellwänden hat, vor allem für die Stabilität von Nerven- und Gliazellen. Außerdem synthetisiert Methionin die nicht-essentielle Aminosäure Cystein (→ Abschnitt 2.3.6), die dem Nervensystem als Radikalfänger dient.
Methionin wird im Gehirn in die aktive Form S-Adenosyl-Methionin umgewandelt. Es ist bei der Herstellung von Acetylcholin, Adrenalin, Dopamin, Glutamat, Glutamin, Histamin, Noradrenalin und Serotonin notwendig, indirekt auch bei der Gamma-Aminobuttersäure (GABA), für die Glutamat eine Vorstufe ist.
Phenylalanin
Die Aminosäure entfaltet im Nervensystem eine hohe Aktivität, unter anderem auch wegen ihrer Bedeutung als Vorstufe der nicht‑essentiellen Aminosäure Tyrosin (→ Abschnitt 2.3.6).
Phenylalanin ist an der Synthese der Neurotransmitter Adrenalin, Dopamin, Levodopa, Noradrenalin, Phenethylamin und Tyramin und am Schilddrüsenhormon Thyroxin beteiligt. Letzteres hat auf die psychische Verfassung Auswirkungen, da die Schilddrüse den Körpergrundumsatz steuert.
Threonin
Threonin kann in die nicht-essentielle Aminosäure Glycin umgewandelt werden und hat nur deshalb im Nervensystem eine höhere Bedeutung (→ Abschnitt 2.3.6).
Tryptophan
Tryptophan ist die Grundlage für die Synthese des Neurotransmitters Serotonin, zu dem es in wenigen Schritten über 5-Hydroxytryptophan umgewandelt wird. Tryptophan spielt daher auch bei der Synthese von Melatonin eine Rolle, denn hier ist Serotonin die Vorstufe.
Auch für die Synthese von Acetylcholin, Adrenalin, Dopamin, Glutamat, Glutamin, Histamin, Noradrenalin und der Gamma-Aminobuttersäure (GABA) wird Tryptophan benötigt.
2.3.6 Nicht-essentielle Aminosäuren
Nicht-essentielle Amionsäuren kann der Körper selber produzieren. Theoretisch müssten sie daher nicht durch die Ernährung zugeführt werden.
Praktisch sieht es aber etwas anders aus, denn zur Herstellung müssen ideale Bedingungen herrschen. Das heißt:
- Alle zur Synthese notwendigen Substanzen sollten in ausreichender Menge vorhanden sein.
- Bei Krankheit, Rekonvaleszenz oder in der Wachstumsphase können die selbst hergestellen Mengen eventuell nicht ausreichen.
Sind die Bedingungen also suboptimal, reichen die körpereigenen Mengen nicht immer aus. Ernährungsmediziner gehen davon aus, dass dann vor allem Alanin, Arginin und Histidin zusätzlich zugeführt werden sollten.
Auch die körpereigene Produktion von Asparagin, Cystein oder Tyrosin steht im Verdacht, in bestimmten Fällen nicht auszureichen.
Nicht-essentielle Aminosäuren, die in Grenzfällen zusätzlich über die Nahrung aufgenommen werden müssen, werden auch als semi‑essentiell oder bedingt essentiell bezeichnet:
- Als semi‑essentiell gelten Aminosäuren, die für ihre Produktion essentielle Aminosäuren benötigen.
- Als bedingt essentiell gelten Aminosäuren, wenn sie in bestimmen körperlichen Ausnahmesituationen zusätzlich über die Ernährung bereitgestellt werden müssen.
Alanin
Alanin ist u. a. für die Regulierung des Blutzuckerspiegels entscheidend, da es bei der Gluconeogenese eine Vorstufe der Glukose ist ‑ und somit für den Verlauf der Blutzuckerkurve mitverantwortlich (→ Abschnitt 4.8.4 ff.). Das ist für Nervenzellen wichtig, die ausschließlich mit Glukose ihren Energiebedarf decken.
Arginin
Arginin erfüllt seine Aufgaben im Blutkreislauf als Botenstoff zur Gefäßerweiterung. Dadurch wird im Gehirn auf unterschiedliche Blutbedarfe reagiert, beispielsweise bei erhöhten Aktivitäten.
Als Vorstufe von Stickstoffmonoxid, ein für die Nervenzellen relevanter Botenstoff und im Gehirn in hoher Menge nachweisbar, ist Arginin für die Funktionalität des Nervensystems relevant. Arginin spielt bei der Entwicklung und Veränderung von Neuronen eine große Rolle. Lern- und Gedächtnisprozesse werden von Arginin beeinflusst.
Asparagin und Asparaginsäure
Bei beiden Aminosäuren handelt es sich um verwandte Substanzen, so dass sie hier der Einfachheit halber gemeinsam beschrieben werden. Im als Asparagin-Asparaginsäure-Kreislauf bezeichneten Stoffwechselzyklus können beide Substanzen ineinander umgewandelt werden. Für die Nukleinsäurensynthese (DNA, RNA) ist die Asparaginsäure grundlegend.
Asparagin ist ein Ausgangsstoff verschiedener Neurotransmitter und Bestandteile vieler Proteine, die im zentralen Nervensystem eine Rolle spielen. Die Asparaginsäure (= L-Aspartat) übernimmt dagegen direkt die Funktion eines stimulierenden Neurotransmitters.
Cystein
Cystein ist Bestandteil fast aller Proteine und damit von großer allgemeiner Bedeutung. Cystein hat eine wichtige Funktion für den Zellschutz, da es ‑ zusammen mit Glycin und Glutamin ‑ an der Synthese des Antioxidans Glutathion beteiligt ist.
Aus Cystein (zusammen mit Methionin und Vitamin B6) wird Taurin gebildet. Taurin hat im Nervensystem vor allem schützende Funktionen, da es ebenfalls antioxidativ wirkt und sowohl die Membranen der Nerven- und Gliazellen stabilisiert als auch die im Gehirn wichtigen essentiellen Fettsäuren vor Oxidation schützt.
Glutamin und Glutaminsäure
Die Aminosäuren sind verwandte Substanzen und haben im Gehirn gegensätzliche Funktionen.
Glutamin, das in der Regel aus der in der Nahrung häufiger vorkommenden Glutaminsäure synthetisiert wird, ist die Vorstufe der Neurotransmitter Glutamat und Gamma‑Aminobuttersäure (GABA). GABA ist der wichtigste inhibitorische Neurotransmitter, wirkt also beruhigend.
Die im Nervensystem direkt synthetisierte Glutaminsäure, also der Teil, der nicht über die Nahrung aufgenommen wird, ist im Gegensatz dazu der wichtigste erregende Neurotransmitter.
Glycin
Für den Energiehaushalt einer Zelle ist Glycin entscheidend. Es ist sowohl für den Zuckerstoffwechsel und die Energieproduktion als auch für die Synthese des roten Blutfarbstoffs Hämoglobin unverzichtbar. Darüber hinaus ist Glycin ein wichtiger inhibitorischer Neurotransmitter mit beruhigender Funktion.
Glycin kann in die nicht-essentielle Aminosäure Serin umgewandelt werden (→ Serin).
Histidin
Histidin ist ‑ wie Glycin ‑ an der Synthese von Hämoglobin beteiligt ‑ und damit für die Sauerstoffversorgung wichtig.
Bei der Synthese der Myelinzellen, den nervenzellenumhüllenden Gliazellen, ist Histidin beteiligt und das ist auch die entscheidende Aufgabe dieser Aminosäure im Nervensystem.
Viele weitere Erkenntnisse über besondere Funktionen des Histidins im Stoffwechsel des Zentralnervensystems gibt es bisher nicht. Einige Quellen verweisen auf Studien, die über bestimmte Zusammenhänge zwischen Histidin und Verhaltensstörungen berichten, aber leider sind deren Ergebnisse relativ spärlich dokumentiert, so dass darüber nicht weiter spekuliert werden soll.
Prolin
Über die Aminosäure Prolin und ihre Beziehungen zum Nervensystem liegt so gut wie nichts vor. Sie hat ‑ wie alle Aminosäuren ‑ eine wichtige allgemeine Bedeutung. Einige Funktionen hat Prolin im Bewegungsapparat, da es dort in allen Gewebearten reichlich vorkommt, nämlich im Bindegewebe, in Knochen und Knorpel und in den Kollagenfasern.
Serin
Einige der Prozesse mit allgemeiner Bedeutung, an denen besonders Serin beteiligt ist, sind auch im Nervensystem entscheidend. Dazu zählen der Kohlenhydratstoffwechsel und der Stoffaustausch durch die Zellmembranen, Letzteres aufgrund der Beteiligung von Serin an der Phosphatlipidsynthese. Die Membranen der Nervenzellen sind vor allem auf Phosphatidylserin angewiesen, das auf Grundlage von Serin hergestellt wird. (→ Abschnitt 2.4.2).
Serin und Glycin können jeweils ineinander umgewandelt werden, was die Funktionalität von Serin steigert und bei Mangelversorgung von Vorteil sein kann.
Cholin ist eine Vorstufe des für Nerven- und Gliazellen wichtigen Phosphatidylcholins und ein weiterer wichtiger Bestandteil von Zellmembranen (→ Abschnitte 2.3.2 und 2.4.2). Cholin benötigt zur Synthese Serin. Cholin ist aber auch die Vorstufe des Botenstoffs Acetylcholin. Acetylcholin ist ein sowohl hemmender als auch aktivierender Botenstoff. Diese Zusammenhänge steigern die Bedeutung des Serins für das Nervensystem erheblich.
D-Serin wird als Botenstoff von bestimmten Gliazellen, den Astrozyten, aber auch in Nervenzellen ausgeschüttet und beeinflusst den Informationsaustausch zwischen den Nervenzellen. D‑Serin bindet an NMDA-Rezeptoren und verstärkt dadurch die Wirkung des Botenstoffs Glutamat. Für die Synthese von D‑Serin ist Serin notwendig.
Tyrosin
Die hohe Bedeutung der Aminosäure Tyrosin ergibt sich aufgrund nachfolgender Beschreibung. Die Leber wandelt Phenylalanin in Tyrosin um.
Tyrosin ist eine Vorstufe der Neurotransmitter Adrenalin, Dopamin, L-Dopa und Noradrenalin. Ebenfalls ist es an der Synthese der für das Gehirn wichtigen Schilddrüsenhormone T3 und T4 beteiligt.
Fast alle signalübertragenden Proteine benötigen zur Herstellung diese Aminosäure. Tyrosin wirkt gleichfalls als erregender Botenstoff.
2.4 Nahrungsfette und Fettbegleitstoffe (Lipide)▲
Der Begriff „Fette“ wird fälschlicherweise als eine Sammelbezeichung für Nahrungsfette, Fettsäuren und fettähnliche Substanzen ‑ wie beispielsweise Cholesterin ‑ verstanden, was wissenschaftlich nicht korrekt ist. Der exakte Oberbegriff dafür ist Lipide.
2.4.1 Nahrungsfette (Glyceride und Fettsäuren)
Nahrungsfette bestehen hauptsächlich aus Glyceriden, den Verbindungen zwischen Glycerin und Fettsäuren. Die Fettsäuren machen den Fettanteil des Moleküls aus, Glycerin gehört zur Gruppe der Alkohole. Es werden Mono‑, Di‑ und Triglyceride unterschieden, je nachdem, ob sich eine, zwei oder drei Fettsäuren mit einem Glycerinmolekül verbinden. Triglyceride machen davon mit ca. 90% den größten Teil aus.
Auch glycerinungebundene freie Fettsäuren sind in geringer Zahl Bestandteile des Nahrungsfetts.
Verschiedene Klassifizierungen von Fettsäuren
Es gibt drei Klassen von Fettsäuren: gesättigte Fettsäuren, einfach ungesättigte Fettsäuren und mehrfach ungesättigte Fettsäuren. Die Bezeichungen beruhen auf Unterschiede der chemischen Bindungen.
Nach Herkunft werden nicht-essentielle Fettsäuren und essentielle Fettsäuren unterschieden. Erstere kann der Körper selber herstellen, die anderen müssen mit der Nahrung aufgenommen werden.
Ausschließlich ungesättigte Fettsäuren werden noch in Omega‑n‑Fettsäuren differenziert, die ebenfalls auf chemischen Besonderheiten der Bindungen beruhen. Es werden Omega‑3‑, Omega‑6‑ und Omega‑9‑Fettsäuren unterschieden. Um keine Verwirrung zu stiften, wird auf diese Nomenklatur hier nicht näher eingegangen.
Was alle Fettsäuren leisten
Fettsäuren dienen der Deckung des Energiebedarfs und als Zellmembranbaustoffe, ungesättigte Fettsäuren übernehmen darüber hinaus noch physiologische Funktionen im Zellstoffwechsel. Bezüglich der Energieversorgung gibt es eine Ausnahme bei Nervenzellen, denn Energie wird dort ausschließlich durch den Abbau von Glukose gewonnen.
Gesättigte Fettsäuren
Auch wenn der Körper gesättigte Fettsäuren selber herstellen kann, gelangen sie vor allem durch den Konsum tierischen Fettes in den Körper. Einige pflanzliche Lebensmittel enthalten ebenfalls gesättigte Fette: Kokosöl besteht beispielsweise überwiegend aus gesättigten und nur zu 6 ‑ 13% aus ungesättigten Fettsäuren.
Gesättigte Fettsäuren dienen aufgrund ihres hohen Energiegehalts vor allem der Energieversorgung. Sie sind Baustoffe für Zellmembranen und haben membranstabilisierende Eigenschaften. Bei einer hohen Zufuhr auf Kosten ungesättigter Fettsäuren besteht die Gefahr zu starrer Zellmembranen.
Gesättigte Fettsäuren können wegen ihrer Bindungsstruktur eigentlich nicht mit anderen Substanzen interagieren und deswegen keine physiologischen Funktionen ausführen. Jedoch mehren sich Hinweise, dass diese Vorstellung eventuell nicht korrekt ist und einige gesättigte Fettsäurearten solche Fähigkeiten haben, wie die nachfolgende Aufzählung zeigt (Quellen: O. Hirschfeld-Kroll 2005, Medizinische Fakultät der Eberhard-Karls-Universität, Tübingen; European Food Information Council, www.eufic.org).
- Buttersäure: Regulation der Proteinbiosynthese, Abwehr maligner Tumorzellen
- Laurinsäure: Beteiligung an der Synthese von mehrfach ungesättigten Fettsäuren
- Myristinsäure: Funktionen bei der Zellkommunikation, Immunfunktion, Regulation der Verfügbarkeit von mehrfach ungesättigten Fettsäuren
- Palmitinsäure: Regulation der Hormonsynthese, Funktionen bei der Zellkommunikation, Immunfunktion
Einfach ungesättigte Fettsäuren
Neben ihrer Energieversorgungsfunktion übernehmen einfach ungesättige Fettsäuren eine Rolle beim Aufbau von Zellmembranen, welche gesättigte Fettsäuren nicht leisten. Membranen werden durch sie flexibel und beweglich, wovon die Membranstruktur und ‑funktion insgesamt sowie die in die Zellwände eingebauten Proteine profitieren, da sie nur so in der Lage sind, ihre Funktionen optimal zu erfüllen, beispielsweise als Rezeptoren: Das Ein- und Ausschleusen von Stoffen oder deren Blockade wird durch flexible Membranen erleichtert.
Auch sie sind ‑ wie die gesättigten Fettsäuren ‑ nicht essentiell, da der Körper sie selber herstellen kann. Die wichtigste Verterterin ist die Ölsäure, die in einigen Pflanzenölen (Rapsöl, Olivenöl) einen besonders hohen Anteil hat. Daneben sind noch Gadoleinsäure und Nervonsäure zu nennen.
Einfach ungesättigte Fettsäuren übernehmen auch physiologische Funktionen, wie beispielsweise die Nervonsäure:
- Überproportionale Nutzung der Nervonsäure als Baustein der Nervenzellmembranen
- Beteiligung an der Myelinsynthese
- Modulierung der Nervenreizübertragung
- Beteiligung am Wachstum von Nervenzellen
- Beteiligung an den Verschaltungsvorgängen von Nervenzellen
- Verhinderung von Mechanismen, die zur Neurodegeneration beitragen
Mehrfach ungesättigte Fettsäuren (PUFA)
Auch diese Fettsäuren sorgen neben der Energieversorgung gemeinsam mit den einfach ungesättigten Fettsäuren für ausreichende Membranflexibilität und übernehmen aufgrund ihrer Fähigkeiten, Verbindungen mit anderen Substanzen einzugehen, eine Vielzahl weiterer Biofunktionen.
PUFA (für den englischen Terminus „Polyunsaturated fatty acids“) sind essentiell oder bedingt essentiell und müssen daher mit dem Nahrungsfett zugeführt werden. Wichtig sind vor allem die Alpha-Linolensäure und die Linolsäure, beide auch Grundlage für die Synthese weiterer mehrfach ungesättigter Fettsäuren.
Mehrfach ungesättigte Fettsäuren sind ursprünglich pflanzlich. Beispielsweise entstammen die PUFA aus Fischen letztlich Algen als Teil ihrer Nahrung. Raubfische ‑ wie Lachse ‑ reichern als deren natürliche Fressfeinde die ursprünglich aus Algen stammenden mehrfach ungesättigten Fettsäuren an.
- Alpha-Linolensäure (ALA)
Ein geringer Teil der essentiellen dreifach ungesättigten Alpha-Linolensäure (ALA) synthetisiert DHA und EPA. Daher treffen die bei DHA/EPA erwähnten positiven Einflüsse indirekt auch auf die ALA zu. ALA unterdrückt die Synthese der entzündungsverstärkenden Arachidonsäure.
- Linolsäure
Die essentielle zweifach ungesättigte Linolsäure dient als Vorstufe der Synthese anderer mehrfach ungesättigter Fettsäuren, dazu gehören Gamma‑Linolensäure, Dihomogamma‑Linolensäure und die Arachidonsäure. Somit ist sie indirekt auch mit deren Eigenschaften in Verbindung zu bringen.
- Docosahexaensäure und Eicosapentaensäure (DHA/EPA)
DHA und EPA gelten als bedingt essentiell, da die körpereigene Synthese durch die Alpha-Linolensäure (ALA) nicht zuverlässig ausreicht.
DHA hat einen Gehirnsubstanzanteil von 15 Prozent, die fettreichen Hirnzellmembranen bestehen zu einem Viertel aus DHA, was für ausreichende Membranbeweglichkeit und optimale Funktionsfähigkeit sorgt. Für die myelinbildenden Gliazellen ist DHA unbedingt notwendig.
EPA ist an der Synthese der Serie-3-Eicosanoide beteiligt, die im Gehirn botenstoffähnliche Wirkungen und entzündungshemmende Aktivitäten entfalten.
- Gamma-Linolensäure
(GLA)
GLA wird im Körper durch die Umwandlung der Linolsäure synthetisiert. Auch durch die Nahrung kann sie in den Körper gelangen, ist jedoch nur in wenigen pflanzlichen Ölen (z. B. Nachtkerzenöl, Borretschöl) enthalten. Die GLA ist die Grundsubstanz der Dihomogamma-Linolensäure (DGLA).
GLA ist essentiell für die Reizverarbeitung. Sie ist in den Nervenzellmembranen auffällig hoch konzentriert und steht dort bei Bedarf zur weiteren Umwandlung in DGLA zur Verfügung.
- Dihomogamma-Linolensäure (DGLA)
DGLA dient der Synthese von Serie-1-Eicosanoiden mit entzündungshemmenden Funktionen. Aber auch für die Arachidonsäure ist DGLA die Vorstufe.
- Arachidonsäure (AA)
Nur tierische Lebewesen können Arachidonsäure aus DGLA synthetisieren, daher ist sie auch nur in tierischen Nahrungsprodukten enthalten.
Die Arachidonsäure wird in Serie-2-Eicosanoide umgewandelt, die mit positiven als auch negativen Eigenschaften verbunden sind. Einerseits werden ihr entzündungsfördernde Eigenschaften nachgesagt, aber es gibt ebenfalls Hinweise auf entzündungshemmende Funktionen. Auch ist zu berücksichtigen, dass Entzündungsprozesse im Körper notwendig sind, beispielsweise dienen sie der Heilung von Verletzungen.
Zur Gruppe der Serie-2-Eicosanoide gehören Endocannabinoide, die noch relativ wenig erforscht sind. Bei ADHS-Patienten wurden geringe Arachidonsäurekonzentrationen festgestellt. Das stimmt mit der Erkenntnis überein, dass Arachidonsäure das Verhalten beeinflusst.
2.4.2 Fettbegleitstoffe
Fettbegleitstoffe sind in Wasser unlöslich und zumeist Bestandteile des Nahrungsfetts. Als Fettbegleitstoffe werden fettähnliche Stoffe, Sterine und fettlösliche Vitamine unterschieden:
- Fettähnliche Stoffe (Lipoide) enthalten als einzige Fettbegleitstoffe auch Fettsäuren, im Nervensystem sind vor allem Phosphatidylcholin (früher Vitamin B4), Phosphatidylinositol (früher Vitamin B8) und Phosphatidylserin von Bedeutung
- Sterine, insbesondere Cholesterin
- Fettlösliche Vitamine
Hinweis: Fettlösliche Vitamine, Phosphatidylcholin und Phosphatidylinositol werden den Mikronährstoffen zugeordnet und sind daher Teile der Abschnitte 2.3 f. Zur Vervollständigung der Darstellung fehlen noch Phosphatidylserin und Cholesterin.
Phosphatidylserin
Phosphatidylserin ist ein wichtiger Teil von Zellmembranen und dort auf der dem Zytoplasma zugewandten Membraninnenseiten lokalisiert.
Es sorgt für Membranflexibilität, so dass Membranproteine optimal in die Membranstruktur integriert werden. Phosphatidylserin befindet sich auffällig verstärkt in räumlicher Nähe zu ihnen. Membanproteine sind u. a. für alle Schaltfunktionen der Zelle verantwortlich. Das betrifft die gesamte Reizverarbeitung der Nervenzellen: die Reizübertragung an den Synapsen und die Reizweiterleitung an den Axonen mit deren Myelinscheiden. Es wird vermutet, dass Phosphatidylserin nicht nur passiv, sondern auch aktiv in Zelloberflächenprozesse involviert ist.
Studien deuten darauf hin, dass Phosphatidylserin auch als Antioxdans Nervenzellen vor Toxinen schützt. Das könnte direkt erfolgen aber auch eine indirekte Folge ihrer Membranfunktionsverbesserung sein, wodurch sich Zellen besser gegen schädliche Eindringlinge schützen können (Quelle: Geiss, Hamm, Waag, Zirkelbach 1999, Wissenschaftliches Dossier zu Phosphatidylserin, ISME GmbH, Mörfelden-Walldorf).
Cholesterin
Der Körper bildet Cholesterin in der Leber, es ist aber auch in tierischen Nahrungsmitteln enthalten. Wird Cholesterin über die Nahrung aufgenommen, drosselt ein effektiver Regelungsmechanismus die Eigenproduktion. Es wird dennoch empfohlen, die täglich mit der Nahrung aufgenommene Menge an Cholesterin auf ca. 300 mg zu begrenzen, denn ein hoher Colesterinspiegel im Blut wird mit Erkrankungen des Herz-Kreislauf-Systems in Zusammenhang gebracht. Der Kausalzusammenhang zwischen hohen Cholesterinwerten und Herz-Kreislauf-Erkrankungen ist jedoch bis heute nicht belegt.
Die üblichen Blutgrenzwerte für das Gesamtcholesterin gesunder Erwachsener liegt bei 200 bis 230 mg/dl. Cholesterinfehlversorgungen werden als Hyper‑ bzw. Hypocholesterinämie bezeichnet.
Ein Gehirn besteht zu ca. 18% aus dem polyzyklischen Alkohol Cholesterin, das damit eine für das Nervensystem wichtige Substanz ist. Belegt ist auch seine Unverzichtbarkeit im gesamten Körper, denn Cholesterin ist...
- Bestandteil aller Zellmembranen,
- Vorstufe der Geschlechtshormone DHEA, Östrogen, Progesteron und Testosteron,
- Vorstufe der Nebennierenhormone Aldosteron und Cortisol und
- Faktor bei der Synthese von Vitamin D.
Cholesterin sorgt für eine gute Zellmembranstabilität und ist mitverantwortlich dafür, dass die Zelle das Ein- und Ausschleusen von Substanzen optimal durchführen kann. Cholesterin arbeitet hier mit anderen membranrelevanten Fettsäuren bzw. Fettbegleitstoffen eng zusammen.
2.5 Integration von Zellprozessbereichen und Zellsubstanzen▲
Ein geeignetes Zellmodell vereinigt die vier Basisprozessbereiche von Kern‑ und Zellteilung, Proteinbiosynthese mit Transkription und Translation, Energieversorgung und Spezialfunktionen und die für den Zellbetrieb notwendigen Basissubstanzen auf einfache Weise.
In den folgenden Abschnitten wird das Zellprozessmodell Schritt für Schritt entwickelt. Die Modellkonstruktion erfolgt auf Grundlage des Parsimonieprinzips: So viele Elemente wie nötig, so wenige wie möglich (→ Abschnitt 2.1).
Prozessebenen als Ausdruck von Abhängigkeiten
Zellen benötigen für sämtliche Aktivitäten Peptide in Form von Enzymen und Proteinen, die durch Transkription und den sich anschließenden Translationsprozess entstehen. Dieser elementare Vorgang der Proteinbiosynthese findet auf einer allen restlichen Prozessen übergeordneten Prozessebene statt. Die Ergebnisse der Proteinbiosynthese ‑ also sämtliche Peptide und die unmittelbar daraus resultierenden Prozesse Kern‑ und Zellteilung, Energieversorgung und Spezialfunktionen ‑ befinden sich demgegenüber auf der unteren Prozessebene, wie die folgende Abbildung 8 verdeutlich.
ABBILDUNG 8: VIER BASISPROZESSGRUPPEN AUF ZWEI ZELLPROZESSEBENEN
Abbildung 8: Die Differenzierung in eine obere und untere Prozessebene zeigt Abhängigkeiten zwischen den Prozessgruppen. Die Proteinbiosynthese (mit Transkription und Translation) produziert auf der übergeordneten Ebene alle Peptide. Die daraus resultierenden restlichen Abläufe (Spezialfunktionen, Energieversorgung, Kern- und Zellteilung) bilden die untere Prozessebene.
Kern- und Zellteilung verbinden beide Prozessebenen
Bei der Modellintegration von Kern‑ und Zellteilung ist noch ein besonderer Aspekt zu berücksichtigen, denn durch diese Prozesse resultieren aus einer Mutterzelle zwei Tochterzellen. Im vereinheitlichenden Zellmodell ist eine explizite Unterscheidung von Mutterzelle und Tocherzellen aber nicht zweckmäßig.
Der Kunstgriff besteht darin, diesen Vorgang als Prozesskreislauf darzustellen, was im Modell problemlos möglich ist. Der braune Prozesspfeil führt daher von der unteren Ebene zur Transkription bzw. mRNA auf der oberen Prozessebene. Dadurch werden beide Zellprozessebenen miteinander verbunden und die Abhängigkeit der Zell‑DNA von den Teilungsprozessen hervorgehoben.
ABBILDUNG 9: KERN- UND ZELLTEILUNG VERBINDEN UNTERE UND OBERE ZELLPROZESSEBENE
Abbildung 9: Kern‑ und Zellteilungsprozesse und die dazu nötigen Enzyme und Proteine gehören zur unteren Zellebene, denn sie resultieren aus der Proteinbiosynthese. Das Ergebnis ihrer Aktivitäten ist eine neue DNA‑Vorlage (Zell‑DNA). Daher muss der braune Prozesspfeil zur Zell‑DNA zurückführen. Es ist ein Prozesskreislauf zwischen oberer und unterer Zellebene entstanden, der eine weitere Abhängigkeit verdeutlicht, denn die Qualität der Zell‑DNA ist auch von einer korrekten Kern‑ bzw. Zellteilung abhängig.
Proteinbiosynthese als zweite Verbindung zwischen den Zellebenen
Die Prozessdarstellung der Proteinbiosynthese ist in Abbildung 8 (bzw. 9) ebenfalls unvollständig. Auch die Proteinbiosynthese ist das Ergebnis der Aktivitäten spezieller Peptide, die mittels Transkription und Translation entstehen, zum Beispiel Polymerasen, Transkriptionsfaktoren oder Ribosomen: Die Proteinbiosynthese produziert somit ihre eigenen Werkzeuge. Diese Tatsache muss auch das Zellmodell widerspiegeln (→ Abbildung 10):
- Die zur Proteinbiosynthese nötigen Peptide ergänzen die untere Prozessebene, denn auch diese Enzyme und Proteine gehören zur unteren Ebene.
- Der grüne Prozesspfeil verweist zurück auf die obere Prozessebene mit Transkription und Translation.
- Im linken Teil der Graphik ergibt sich damit ein zweiter Prozesskreislauf, der beide Zellebenen verbindet.
ABBILDUNG 10: DIE PROTEINBIOSYNTHESE BILDET EINEN WEITEREN PROZESSKREISLAUF
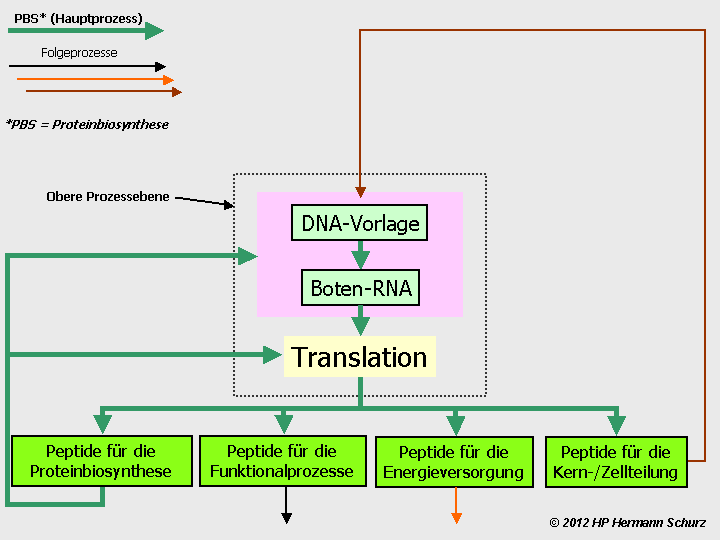
Abbildung 10: Die Peptide zur Durchführung der Proteinbiosynthese sind ebenfalls Ergebnisse von Transkription und Translation. Die Proteinbiosynthese ist damit ihr eigener Werkzeuglieferant, was durch den links dargestellten Prozesskreislauf zum Ausdruck kommt, der eine zweite Verbindung zwischen unterer und oberer Prozessebene herstellt.
Zellprozessmodell und nicht-codierende Ribonukleinsäuren (ncRNA)
Ohne ncRNA funktionieren weder Kernteilung noch Proteinbiosynthese - und ohne ncRNA bliebe auch das Zellprozessmodell unvollständig:
- Primer‑RNA initiieren die DNA‑Replikation als ersten Schritt einer Prozesskaskade, die mit der Zellteilung endet.
- Verschiedene Formen nicht-codierender Ribonukleinsäuren, beispielsweise micro‑RNA (miRNA), modulieren und steuern die Proteinbiosynthese (Transkription und Translation) mittels RNAi‑ und RNAa‑Prozessen.
- Transfer-RNA (tRNA) und ribosomale RNA (rRNA) sind unverzichtbar für den Aufbau der Aminosäureketten während des Translationsprozesses.
Die folgende Abbildung 11 trägt dem Rechnung, indem die wichtigsten RNA-Moleküle in die Prozessdarstellung integriert wurden.
ABBILDUNG 11: MODELLINTEGRATION NICHT-CODIERENDER RIBONUKLEINSÄUREN
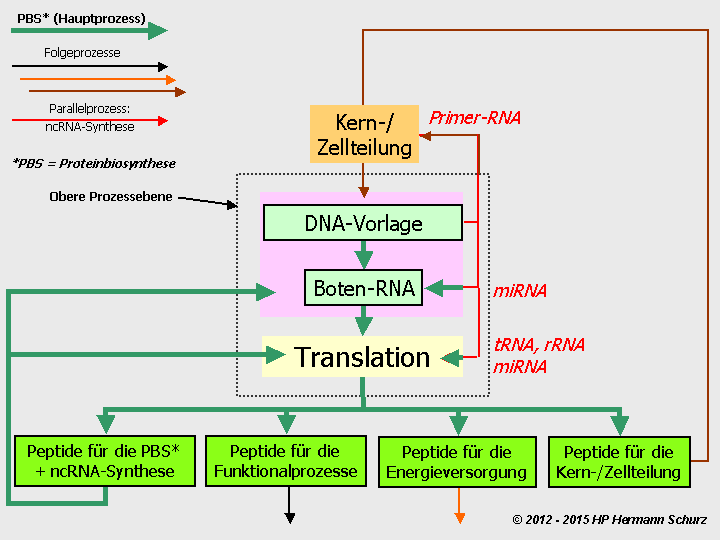
Abbildung 11: Nicht‑codierende Ribonukleinsäuren (Primer, miRNA, tRNA und rRNA) sind das Resultat von Transkriptionsprozessen, eine Translation in Peptide findet nicht statt. Primer starten die Kernteilung durch Initiierung der DNA‑Replikation, für die Durchführung der Translation werden tRNA und rRNA benötigt. Interessant sind vor allem die genregulierenden ncRNA, die eine korrekte zelltyp‑ und funktionsspezifische Proteinbiosynthese garantieren. Um das Zellmodell nicht zu überfrachten, werden sie aus ausschließlich durch micro‑RNA (miRNA) repräsentiert.
Ein dritter Prozesskreislauf durch ncRNA
Auf den ersten Blick scheint es so, als gehörten ncRNA-Moleküle zur oberen Zellprozessebene, denn dort entstehen sie und dort erledigen die meisten ihre Aufgaben, beispielsweise als Genregulatoren. Ausnahmen sind RNA‑Primer, die mit der DNA‑Replikation einen Vorgang starten, der zur Kern‑ und Zellteilung gehört und Teil der unteren Zellprozessebene ist. Unterschiedliche Zuordnungen innerhalb der ncRNA‑Molekülklasse wären aber inkonsequent.
Ein Vergleich der ncRNA mit Enzymen und Proteinen (Peptiden) legt darüber hinaus nahe, sämtliche ncRNA‑Moleküle der unteren Prozessebene zuzuordnen, denn sie haben einen mit Peptiden vergleichbaren Ursprung. Wenn Peptide als Ergebnisse der Proteinbiosynthese erklärtermaßen zur unteren Zellebene gehören, dann muss das als Konsequenz auch für ncRNA‑Moleküle gelten, die das Ergebnis eines Teilprozesses der Proteinbiosynthese sind: der Transkription. Nicht-codierende Ribonukleinsäuren gehören demnach nicht zur direkten Linie des Proteinsyntheseprozesses, dem als Substanzen nur die Zell‑DNA und die mRNA zugeordnet sind.
Was für die ncRNA als Substanzen zutrifft, gilt aber nicht für die von ihnen durchzuführenden Aktivitäten RNAi und RNAa und natürlich ebenfalls nicht für die Translationsaktivitäten von tRNA und rRNA. Diese Prozesse gehören zur oberen Zellprozessebene, denn sie sind ein untrennbarer Teil der Proteinbiosynthese. Genregulierende miRNA‑Moleküle steuern die Proteinsynthese bildlich gesprochen „von der Seitenlinie“, tRNA und rRNA arbeiten mit verschiedenen Peptiden bei der Translation zusammen.
Ausnahmen hiervon sind nur die Primer-RNA, deren Aktivitäten für die Kernteilung auf der unteren Prozessebene stattfinden.
Durch die Differenzierung zwischen den genregulierenen RNA, tRNA und rRNA als zur unteren Prozessebene zugehörigen Substanzen und deren Aktivitäten als zur oberen Prozessebene zugehörig ergibt sich ein weiterer ‑ dritter ‑ Prozesskreislauf. Auch in Abbildung 11 wird das durch die entsprechenden roten Graphikelemente deutlich.
Erbinformation der Elterngeneration als weiteres Modellelement
Abbildung 11 zeigt eine hochaggregierte Zellprozessübersicht, die trotz ihrer Vereinfachung vollständig ist. Auch einige für die Durchführung der Prozesse notwendige Zellsubstanzen (Zell‑DNA, mRNA, verschiedene ncRNA und Peptide) sind schon enthalten.
Aber es fehlen noch entscheidende Elemente. So ist auch die Herkunft der Zell‑DNA („DNA‑Vorlage“) im Modell zu berücksichtigen, denn die fällt bekanntermaßen „nicht vom Himmel“.
Die ursprüngliche Erbinformation entsteht durch das Verschmelzen einer männlichen mit einer weiblichen Keimzelle. Die erste Zelle des neuen Lebewesens (Zygote) enthält damit bereits eine vollständige genetische Information (Genom).
Aus der Zygote gehen nach der ersten Teilung zwei Tochterzellen mit einer idealerweise identischen DNA hervor. Damit ist nicht nur die Zygote selber verschwunden, auch deren erste vollständige Erbinformation ist in der Zell‑DNA aufgegangen.
Die ursprüngliche Erbinformation spielt im Modell deshalb eine indirekte Rolle, denn sie ist ein Element aus der Vergangenheit, das nicht mehr exisitiert und nicht aktiv in die Abläufe eingebunden sein kann. Diese Aufgabe übernimmt für alle nachfolgenden Zellen die Zell‑DNA als Teil des Proteinbiosyntheseprozesses (→ Abbildung 12).
ABBILDUNG 12: DIE URSPRÜNGLICHE ERBINFORMATION IM ZELLMODELL
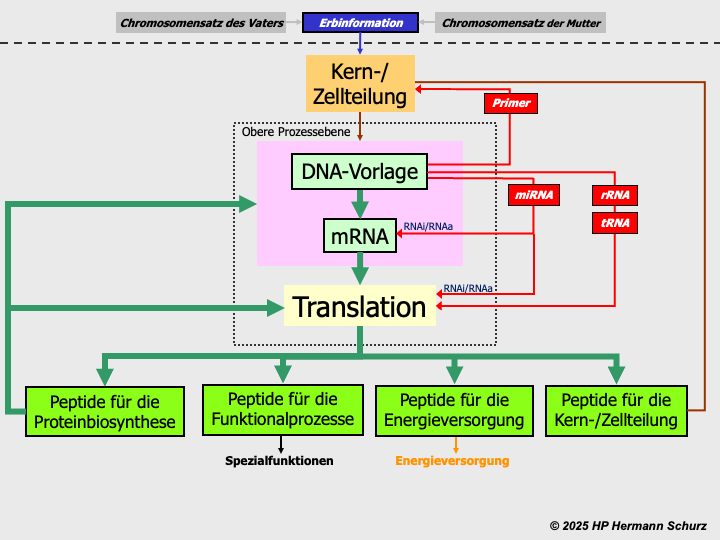
Abbildung 12: Das komplette Genom der Zygote wird im Modell als (ursprüngliche) Erbinformation bezeichnet. Sie geht mit der ersten Zellteilung unmittelbar in die Zell‑DNA („DNA‑Vorlage“) über. Die Zell-DNA wird bei jedem Proteinbiosynthesevorgang aktiv und bei jeder Zellteilung an die nächste Zellgeneration weitergegeben.
Vervollständigung des Zellmodells
Das Modell in Abbildung 12 ist schon fast vollständig, aber noch mit den Basissubstanzen zu ergänzen, ohne die keine Zelle funktionieren würde. Dazu gehören u. a. die in den Abschnitten 2.3 f. aufgezählten Nährstoffe:
- Mikronährstoffe in Form von Vitaminen, vitaminähnlichen Substanzen/Vitaminoiden, Mineralstoffen/Elektrolyten und Spurenelementen.
- Makronährstoffe in Form von essentiellen und nicht-essentiellen Aminosäuren, Nahrungsfetten, Glyceriden/Fettsäuren (Lipiden) und Fettbegleitstoffen (Lipoiden).
Für die Energiegewinnung sind folgende Moleküle essentiell:
- Glukose gehört zur Gruppe der Makronährstoffe und ist die Grundlage für Energiegewinnung und Zellatmung. Das gilt besonders für Nervenzellen, die ihre Energie ausschließlich aus Glukose gewinnen.
- Molekularer Sauerstoff (O2) ist für die Energiegewinnung ebenfalls unentbehrlich und zwingend Teil des Zellprozessmodells.
Wasser (H2O) erfüllt wichtige Grundaufgaben, ohne Wasser ist kein irdisches Leben denkbar:
- Der menschliche Körper besteht zu ca. 70% aus Wasser, es ist in allen Körperzellen und Körperflüssigkeiten vorhanden.
- Außer den wenigen fettlöslichen sind fast alle Körpersubstanzen in Wasser gelöst. Mit Hilfe des Wassers werden alle Nährstoffe im Blut und der Lymphflüssigkeit zu den Organen transportiert. Blutplasma besteht zu 90 ‑ 95% aus Wasser.
- Nur mit Hilfe von Verdauungssekreten, die größtenteils aus Wasser bestehen, kann Nahrung aufgespalten und ihre Bestandteile in den Körper aufgenommen werden.
- Wasser ist hauptsächlich für die Steuerung des osmotischen Drucks zwischen dem Zellinneren und Zelläußeren verantwortlich.
- Wasser dient der Kühlung. Bei hohen Temperaturen verdunstet das Körperwasser über die Haut, wobei überflüssige Wärme entzogen wird.
Die Basissubstanzen werden der Zelle hauptsächlich von außen zugeführt, Nährstoffe und Wasser über die Nahrung, Sauerstoff als einzige Ausnahme über die Lungenatmung. Einige Teilsubstanzen, beispielsweise nicht-essentielle Aminosäuren, können von Zellen synthetisiert werden, allerdings nur mit Hilfe anderer, von außen zugeführter Basissubstanzen.
ABBILDUNG 13: VOLLSTÄNDIGES ZELLPROZESSMODELL
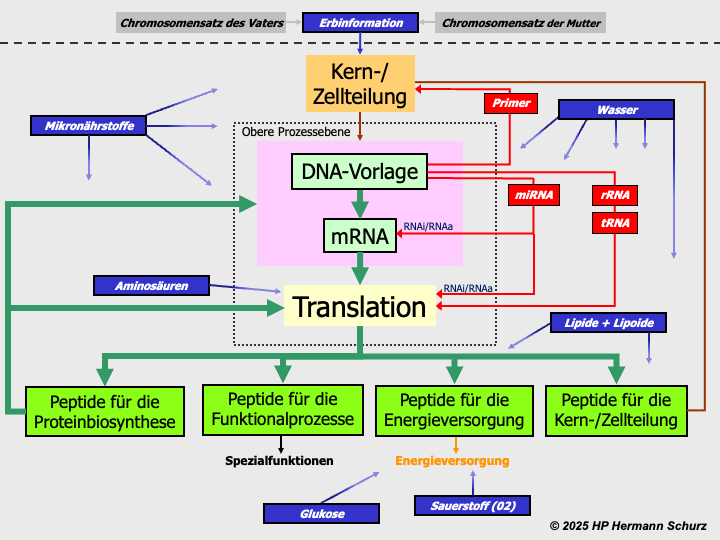
Abbildung 13: Mit der Aufnahme von weiteren sechs Basissubstanzen bzw. Basissubstanzengruppen ist die Konstruktion des Zellprozessmodells abgeschlossen. Mikronährstoffe und Wasser sind überalll im Stoffwechsel von Bedeutung, Glukose und Sauerstoff dagegen fast ausschließlich für die Energieversorgung. Lipide und Lipoide spielen bei der Energieversorgung, der Konstruktion von Membranen und der Hormonsynthese entscheidende Rollen. Aminosäuren sind vor allem die Baustoffe der Proteinsynthese, können aber auch bei der Engergieversorgung eine Rolle spielen.
Übersicht: Die Elemente des Zellprozessmodells
Das Zellprozessmodell besteht aus Strukturen, die für eine Zellschwachstellenanalyse notwendig sind und verzichtet auf überflüssigen Ballast. Es ist ein Minimalmodell im Sinne des Ockham'schen Parsimonieprinzips und weist zwei grundlegende Elementgruppen auf:
- Prozessstrukturen
- Obere Prozessebene mit Proteinbiosynthese.
- Untere Prozessebene mit allen restlichen Prozessen (Kern‑/Zellteilung, Energieversorgung, Spezialfunktionen).
- Drei Prozesskreisläufe schaffen jeweils eine Verbindung zwischen unterer und oberer Zellprozessebene.
- Zellsubstanzen
- Erbinformation als Vorläufer der Zell‑DNA, die ihren Platz außerhalb der Zellprozessebenen hat.
- Zell‑DNA, die aus der Erbinformation hervorgeht und als Vorlage der Transkription sämtlicher Ribonukleinsäuren dient.
- Messenger-RNA (mRNA) als das Hauptergebnis der Transkription und Blaupause für die Translation in Enzyme und Proteine (Peptide).
- Nicht-codierende Ribonukleinsäuren (ncRNA), beispielsweise miRNA, tRNA, Primer, rRNA oder lnRNA, als weitere Substanzen, die durch Transkription entstehen.
- Peptide (Enzyme, Proteine) als Endprodukte des Translationsprozesses.
- Makronährstoffe in Form von Fettsäuren, Fettbegleitstoffen, Glukose und Aminosäuren.
- Mikronährstoffe in Form von Vitaminen, vitaminähnlichen Substanzen, Mineralstoffen und Spurenelementen.
- Sauerstoff (O2) und Wasser (H2O).
Charakteristika der Zellsubstanzen
Bei den Zellsubstanzen handelt es sich um eine heterogene Gruppe unterschiedlicher Herkunft und mit sehr verschiedenen Eigenschaften. Eine Differenzierung in drei Substanzklassen bietet sich an:
- Zwischensubstanzen innerhalb des Proteinbiosyntheseprozesses
- Zell-DNA als Vorlage für die Transkription.
- Messenger-RNA (mRNA) als Vorlage für die Translation.
- Zielsubstanzen des Proteinbiosyntheseprozesses
- Enzyme und Proteine (Peptide) als die Ergebnisse der gesamten Proteinbiosynthese mit der Abfolge von Transkriptions- und Translationsprozessen.
- Acht Faktoren
Alle restlichen acht Substanzen. Sie sind die entscheidenden Antreiber und wesentliche Voraussetzungen für die korrekte Durchführung aller Prozesse. Dieser Rolle entsprechend sind sie als Faktoren zu bezeichnen.
Sieben Faktoren gelangen von außen in das Zellmodell, die nicht-codierenden RNA werden als einzige Faktorengruppe von einer Zelle selbstständig synthetisiert.
Zum nächsten Kapitel 3 - Analyse der Zellschwachstellen - bitte hier klicken: ►