[ Deutsch ] [ English ] [ Русский ]
Herzlich willkommen!
molekulartherapie.de
Eine universelle Theorie & Therapie der Erkrankungen des zentralen Nervensystems
Zellschwachstellenanalyse
3. Identifizierung und Bewertung der Zellschwachstellen ▲
Auf Grundlage des in Kapitel 2 entwickelten Zellprozessmodells wird der Stoffwechsel nun mit Hilfe von Ursachen-Wirkungs-Analysen auf Zellschwachstellen untersucht.
Die Aufgabe besteht nicht nur darin, sämtliche Zellschwachstellen zu identifizieren; diese müssen anschließend auch hinsichtlich ihrer Relevanz bewertet werden, Zellstörungen auslösen zu können.
Ein kurzer Rückblick auf die Kapitel 1 und 2
Affektive Erkrankungen basieren aus kausaltheoretischer Perspektive auf komplexen Neuronenfunktionsstörungen in den für die Verarbeitung von Emotionen und Affekten betroffenen Hirnarealen.
Zentral ist die Annahme eines dreistufigen Degenerationsverlaufs in einem Verbund von Nerven‑ und Gliazellen, der als 3‑Stufen‑Modell bezeichnet wird. Beginnend mit Stufe 1 und Reizverarbeitungsstörungen von Nervenzellen bzw. Aktivitätsstörungen von Gliazellen, geht diese in eine Stufe 2 über, für die der Abbau von Nervenzellenverbindungen charakteristisch ist. In der letzten Stufe ‑ Stufe 3 ‑ findet ein Abbau von Nerven- und Gliazellen statt.
Um die potentiellen Auslöser dieses Szenarios identifizieren zu können, muss zunächst definiert werden, was unter einer fehlerhaften Reizverarbeitung überhaupt zu verstehen ist.
Eine korrekte Reizverarbeitung lässt sich folgendermaßen beschreiben:
- Reize werden bei Bedarf ausgelöst bzw. nicht ausgelöst,
- Reize werden bei Bedarf empfangen bzw. nicht empfangen,
- Reize werden bei Bedarf übertragen bzw. nicht übertragen und
- Reize werden bei Bedarf weitergeleitet bzw. nicht weitergeleitet.
Eine fehlerhafte Reizverarbeitung ist durch krankhaft reduzierte bzw. krankhaft erhöhte Zellaktivitäten charakterisiert:
- Reize, die ausgelöst werden sollen, werden nicht ausgelöst.
- Reize, die nicht ausgelöst werden sollen, werden ausgelöst.
- Reize, die empfangen werden sollen, werden nicht oder fehlerhaft empfangen.
- Reize, die nicht empfangen werden sollen, werden empfangen.
- Reize, die weitergeleitet werden sollen, werden nicht oder fehlerhaft weitergeleitet.
- Reize, die nicht weitergeleitet werden sollen, werden weitergeleitet.
- Reize, die übertragen werden sollen, werden nicht oder fehlerhaft übertragen.
- Reize, die nicht übertragen werden sollen, werden übertragen.
Die Fehler der Reizverarbeitung resultieren wiederum aus einzelnen oder einem Mix endogener Zellprozessstörungen, welche das auf Stufe 1 beschriebene Szenario des 3-Stufen-Modells verursachen. Darüber hinaus haben Zellprozess- und Reizverarbeitungsstörungen der ersten Stufe eine initiale Wirkung für den weiteren Verlauf. Dabei kommt es kurz-, mittel- oder langfristig aufgrund verschiedener Erschöpfungs- bzw. Dominoeffekte zu einem stetigen Abbau der Nervenzellenvernetzung (Modellstufe 2) und einem Untergang von Glia- und Nervenzellen (Modellstufe 3).
Folgende Störungen endogener Zellprozesse sind zu unterscheiden:
- Notwendige, die Reizverarbeitung aktivierende endogene Zellprozesse sind zu langsam.
- Notwendige, die Reizverarbeitung aktivierende endogene Zellprozesse sind unvollständig.
- Notwendige, die Reizverarbeitung aktivierende endogene Zellprozesse werden nicht durchgeführt.
- Notwendige, die Reizverarbeitung aktivierende endogene Zellprozesse sind überaktiv.
- Notwendige, die Reizverarbeitung hemmende endogene Zellprozesse sind zu langsam.
- Notwendige, die Reizverarbeitung hemmende endogene Zellprozesse sind unvollständig.
- Notwendige, die Reizverarbeitung hemmende endogene Zellprozesse werden nicht durchgeführt.
- Notwendige, die Reizverarbeitung hemmende endogene Zellprozesse sind überaktiv.
Diese acht Störungen resultieren wiederum aus noch unbekannten, im hochkomplexen Zellstoffwechsel begründeten Primärursachen. Und genau diese Primärursachen müssen nun identifziert und bewertet werden.
Die Komplexität der Zellabläufe stellt für eine Analyse allerdings eine große Herausforderung dar. Daher bedarf es eines aggregierten Zellprozessmodells, das den Stoffwechsel auf die wesentlichen Prozesse und Substanzen reduziert und dabei dennoch alle Abläufe in einer Zelle korrekt abbildet.
Mit nur vier Zellprozesstypen lässt sich der gesamte Stoffwechsel einer Zelle vollständig darstellen:
- Proteinbiosyntheseprozess,
- Zellteilungsprozess,
- Energieversorgungsprozesse und die
- Funktionalprozesse (alle restlichen Prozesse, mit der eine Zelle ihre speziellen Aufgaben durchführt).
Das Zellmodell gliedert sich im Wesentlichen in eine untere und obere Prozessebene. Die Proteinbiosynthese mit ihren Informationsüberträgersubstanzen Zell-DNA und mRNA und die Transkription verschiedener nicht-codierender RNA finden auf der oberen Zellprozessebene statt, während die Ergebnisse der Proteinsynthese in Form von Enzymen und Proteinen und die Prozesse Zellteilung, Energieversorgung und Spezialprozesse die untere Zellsprozessebene bilden.
Zur Prozessdurchführung bedarf es darüber hinaus noch Faktoren. Faktoren sind Substanzen und bilden die Basis, mit denen alle Zellprozesse ausgeführt werden. Zur Gruppe der Faktoren gehören beispielsweise die verschiedenen nicht-codierenden Ribonukleinsäuren, die auf der oberen Zellprozessebene mittels Transkription produziert werden. Insgesamt verfügt die Zelle über acht Faktoren bzw. Faktorgruppen:
- Aminosäuren,
- die ursprüngliche Erbinformation der Eltern,
- Kohlenhydrate,
- Mikronährstoffe,
- Nahrungsfette und Fettbegleitstoffe,
- nicht-codierende Ribonukleinsäuren,
- Sauerstoff und
- Wasser.
3.1 Grundlegendes über Kausalität und den Zellstoffwechsel ▲
Kausalität, Korrelation, Koinzidenz und Kausalkette
Kausalität liegt vor, wenn es einen eindeutigen Zusammenhang zwischen Ursache und Wirkung gibt. Das Gegenteil von Kausalität ist Zufall oder Chaos.
Wenn beobachtet wird, dass einem Ereignis 2 immer ein bestimmtes anderes Ereignis 1 vorangeht, liegt nicht unbedingt ein Kausalzusammenhang vor, es könnte sich auch nur um eine Korrelation handeln: Ereignis 2 tritt zwar zeitlich immer nach Ereignis 1 ein, Ereignis 2 wurde aber nicht von Ereignis 1 ausgelöst, sondern ein anderes Ereignis 0 ist die Ursache für beide. Ereignis 1 und 2 korrelieren damit lediglich miteinander, haben aber keine Ursache‑Wirkungs‑Beziehung.
Die Bedingung für das Vorliegen von Kausalität muss daher sehr restriktiv formuliert werden. Eine Ursache‑Wirkungs‑Beziehung zwischen einem Ereignis 1 und 2 liegt nur vor, wenn...
- das Ereignis 1 immer dem Ereignis 2 vorangeht und
- das Ereignis 2 nicht ohne das Ereignis 1 eingetreten wäre.
Neben Korrelation und Kausalität können zwei Ereignisse, die scheinbar in Beziehung miteinander stehen, dennoch völlig unabhängig voneinander sein. In diesem Falle beruht das ggf. auch mehrfache zeitliche Aufeinanderfolgen der Ereignisse lediglich auf Zufall, was in der Fachterminologie als Koinzidenz bezeichnet wird.
Weiter ist die Möglichkeit der Existenz mehrerer Ursache-Wirkungs-Ebenen zu beachten: Eine Wirkung kann auch aus einer Ursache resultieren, die wiederum auf einem anderen Ereignis beruht. In diesem Falle liegt eine Kausalkette vor, die theoretisch beliebig lang sein kann.
In einer Kausalkette haben Störungen gleich zu Beginn häufig einen starken und besonders negativen Einfluss auf alle nachfolgenden Ereignisse.
Die Verwechslung von Kausalität und Korrelation, fehlerhafte Deutungen zufälliger Ereignisse oder das Übersehen von Kausalketten führt in allen Wissenschaften bis heute immer wieder zu schweren Missverständnissen und Fehlinterpretationen - leider vor allem in der Psychiatrie und Psychologie.
Abbildung 14 visualisiert die beschriebenen Zusammenhänge und erleichtert das Verständnis.
ABBILDUNG 14: KAUSALITÄT, KORRELATION, KOINZIDENZ UND KAUSALKETTE
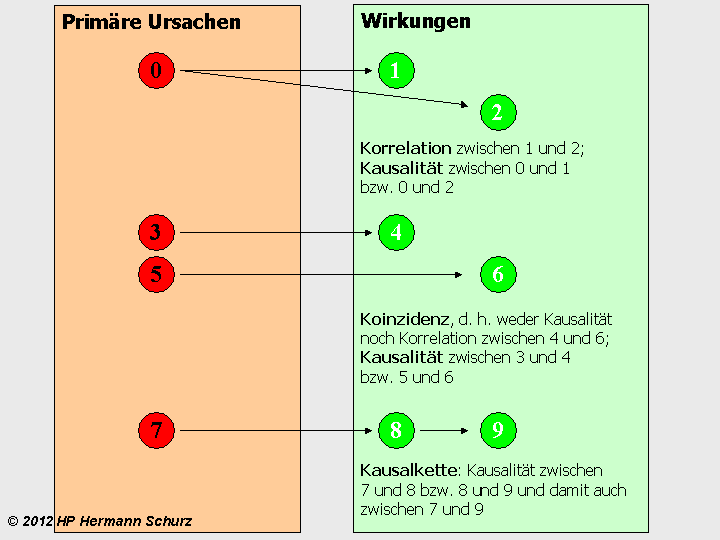
Abbildung 14: Im grünen Rechteck symbolisieren links und rechts platzierte Ereignisse zeitliche Abstände. Die linken Ereignisse 1, 4 und 8 liegen jeweils zeitlich vor den Ereignissen 2, 6 und 9. Im oberen Beispiel liegt zwischen den Ereignissen 1 und 2 eine Korrelation vor, denn beide treten zwar immer nach dem Ereignis 0 auf, aber Ereignis 1 ist nicht die Ursache für Ereignis 2, auch wenn das zeitlich später eintretende Ereignis 2 einen solchen Kausalzusammenhang suggeriert. Im mittleren Beispiel gibt es überhaupt keine Zusammenhänge zwischen 4 und 6, d. h. es liegt weder eine Korrelation noch eine Kausalität vor, denn die Ereignisse 4 und 6 beruhen jeweils auf den verschiedenen Ereignissen 3 und 5, und das zeitliche Aufeinanderfolgen ist rein zufällig, was auch als Koinzidenz bezeichnet wird. Das untere Beispiel zeigt zwei aufeinanderfolgende kausale Zusammenhänge: Ereignis 8 beruht auf Ereignis 7 und würde ohne dieses nicht eintreten. Ereignis 9 beruht wiederum auf Ereignis 8, so dass sich ein fortgesetzter Kausalzusammenhang ergibt. Derartige Ereignisfolgen werden als Kausalkette bezeichnet.
Kausalbeziehungen im Zellprozessmodell
Die Ursache-Wirkungs-Beziehungen in der Zelle entsprechen bei den Proteinbiosyntheseprozessen und der Kern‑ und Zellteilung jeweils der speziellen Form einer Kausalkette, die als zyklische oder kreisförmige Kausalkette bezeichnet wird (→ Abbildung 13 in Abschnitt 2.6 und die folgende Abbildung 15). Durch die kreisförmig angeordneten Wirkungsabfolgen und die dadurch bedingte Eigenschaft jeder Wirkung, immer auch Ursache der nachfolgenden Wirkung zu sein, ist die Identifikation eines eindeutig verursachenden Beginnprozesses nicht möglich. Außerdem gibt es noch ein komplexes Ineinandergreifen von Abläufen, beispielsweise durch Energieversorgungsprozesse.
Aus allem resultiert die Schwierigkeit, einen oder mehrere Prozesse als Ursachen für spätere Ablaufstörungen zu identifizieren.
In der Zelle existieren jedoch relative Kausalitäten, wenn bestimmte Ursache‑Wirkungs‑Abfolgen auf eine sinnvolle Weise isoliert betrachtet werden. Die für sämtliche Prozesse wichtigen Peptide resultieren kausal aus den Vorgängen der Proteinbiosynthese, also aus der Abfolge Transkription → Translation. Es besteht eine relative kausale Beziehung zwischen der Proteinbiosynthese und den in allen Prozessen notwendigen Peptiden:
Transkription → Translation → Peptide
Transkription und Translation bilden die übergeordnete Prozessebene, Peptide die abhängige Ebene. Eine derartige Bewertung der Prozessebenen ist den Abbildungen 8 bis 13 (→ Kapitel 2) zwar schon angedeutet, jedoch werden dort noch die relativ neutralen Begriffe „oberere“ und „untere“ Prozessebene bzw. „Hauptprozess“ für die Proteinbiosynthese verwendet:
Transkription → Translation → Peptide → Zellprozesse
Eine fehlerhafte Proteinbiosynthese ist aufgrund ihrer Stellung und Dominanz damit ebenfalls hauptveranwortlich für Peptidschäden oder -mangel und sämtliche daraus resultierenden Prozessstörungen:
Transkriptionsfehler → Translation gestört → Peptidmängel → Zellprozessfehler
(Transkription →) Translation gestört → Peptidmängel → Zellprozessfehler
Bezogen auf das Hauptanliegen, Verursacher von Zellprozessstörungen exakt einzugrenzen und zu benennen, ist man nun einen Schritt näher an der Lösung. Aber das reicht leider noch nicht.
ABBILDUNG 15: KREISFÖRMIGE ABHÄNGIGKEITEN UND RELATIVE KAUSALITÄT IN EINER ZELLE
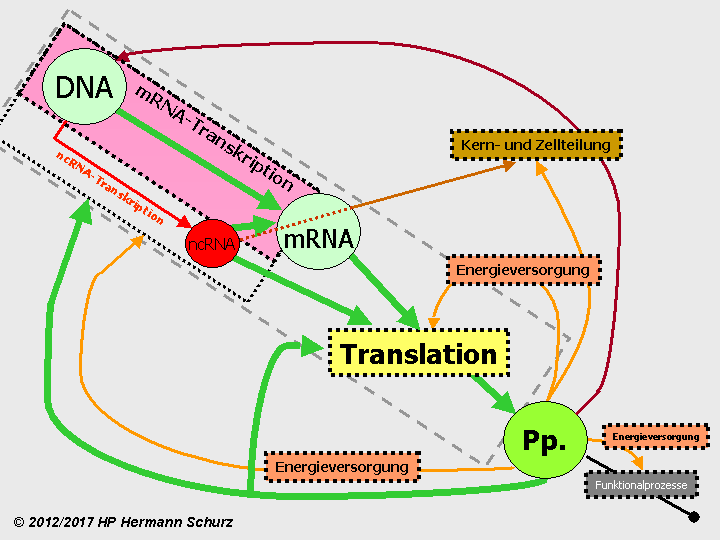
Abbildung 15: Ist die eindeutige Identifikation eines Beginnprozesses oder des Ortes einer Primärursache für Abläufe oder gestörte Abläufe möglich? Auf den ersten Blick Fehlanzeige, denn es existieren zwei kreisförmige Kausalketten (Proteinbiosynthese, Kern- und Zellteilung) und Prozesse beeinflussen sich darüber hinaus gegenseitig, beispielsweise durch die Energiebereitstellung. Zell‑DNA und mRNA (für Boten‑RNA) sind jedoch für die späteren Peptide (Pp.) notwendige Vorlagen bzw. Zwischenprodukte und zentrale Bestandteile von Transkription und Translation. Transkription und Translation sind daher relativ von den Peptiden aus gesehen die Ursachen für deren Existenz. Es existiert aus diesem Grunde eine relative Kausalität der Prozessabfolge innerhalb des grau‑gestrichelt umrandeten Bereichs. Hauptsächlich steuern Peptide wiederum sämtliche Prozesse auf der unteren Ebene (Funktionalprozesse, Energieversorgung, Kern‑ und Zellteilung) und auch die Proteinbiosynthese selber. Transkription, einschließlich der ncRNA‑Transkription (roter Pfeil), und Translation sind die einzigen Abläufe auf der oberen Ebene. Transkription und Translation sind damit untrennbar mit sämtlichen Zellabläufe verbunden und Teile von ihnen. Der fett hervorgehobene grüne Pfeil verdeutlicht den Prozess, indem er Zell‑DNA, mRNA (für Boten‑RNA) und Pp./Peptide miteinander verbindet. All das spricht dafür, Transkription und Translation zusammen als „Primus inter pares“ sämtlicher Prozesse und damit als Hauptprozess zu charakterisieren.
Monokausalität der Gene versus Entwicklungssystemtheorie
Vielleicht helfen an dieser Stelle zwei theoretische Konzepte weiter, die sich ebenfalls mit den Kausalbeziehungen im Zellstoffwechsel auseinandersetzen. Bringen sie bezüglich der Frage nach Ursachen für Zellprozessstörungen die Lösung?
Beide repräsentieren zwei gegensätzliche Ansichten. Die Anhänger der einen Gruppe gehen von einer monokausalen Beziehung zwischen der Zell-DNA als Sammlung aller Gene und den dann stattfindenden Zellprozessen aus, die Verfechter der zweiten Gruppe ziehen mit der Entwicklungssystemtheorie den gegenteiligen Standpunkt vor. Die Entwicklungssystemtheorie wurde von der amerikanischen Wissenschaftsphilosophin Susan Oyama im Jahr 1985 erstmals geäußert.
Die erste Gruppe sieht in den Genen die alleinigen Verantwortlichen der Zellprozesse, die zweite Gruppe der Entwicklungssystemtheoretiker glaubt, dass alle Zellbestandteile ‑ also die damals bekannten Bestandteile Gene, tRNA, rRNA, Enzyme und Proteine ‑ gleichwertig hinsichtlich ihrer Wirkungen sind. Die Gene sind hier nur eine Gruppe von vielen Akteuren, die das Zellgeschehen beeinflussen.
Um die Eignung der These der Monokausalität der Gene für die Suche nach Ursachen für Zellprozessstörungen zu prüfen, muss man deren Anhängern nur folgende triviale Frage stellen: Was passiert mit einem Organismus, der eine Woche lang keinen Zugang zu Trinkwasser erhält oder an der Infektion mit einem tödlichen Erreger erkrankt? Da mit fast 100%iger Sicherheit der Wassermangel bzw. die Infektion und nicht ein genetischer Defekt für sein Ableben verantwortlich sein wird, erübrigt sich jede weitere Diskussion. Die ursprüngliche Erbinformation oder die Zell-DNA können daher niemals Zellprozessstörungen alleine verursachen noch sind sie einzig für die Abläufe in den Zellen verantwortlich. Auch das Zellprozessmodell zeigt, dass die Zell-DNA durch komplizierte Mechanismen, zum Beispiel durch micro-RNA (waren 1985 noch unbekannt) und Steuerungspeptide, interpretiert werden müssen und ihre Entstehung überhaupt der Zusammenarbeit vieler Enzyme, Proteine, RNA und von außen zugefügter Faktoren zu verdanken haben.
Dennoch ist die Meinung, dass viele oder sogar die meisten Erkrankungen genetisch im Sinne von „erblich bedingt“ sind, leider stark verbreitet. Bei Erkrankungen mit unbekannter Ursache werden häufig „die Gene“ in die Verantwortung genommen. Zwar liegt es auf der Hand, dass die ursprüngliche Erbinformation eine große Bedeutung hat, das rechtfertigt aber nicht die Bequemlichkeit, immer dann auf sie zu verweisen, wenn man sonst keine andere Erklärung parat hat.
Ein Blick auf das Zellprozessmodell (→ Abbildung 13, Abschnitt 2.6) zeigt, dass die These der alleinigen Dominanz der Gene auch noch eine weitere wesentliche Schwäche hat. Denn der Begriff „Gene“ macht hier keinen Unterschied zwischen der ursprünglichen Erbinformation und der späteren Zell‑DNA‑Vorlage für die Proteinbiosynthese. Das Zellprozessmodell jedoch unterscheidet diese beiden verschiedenen Aspekte.
Wie plausibel sind die Ansichten der Entwicklungssystemtheoretiker, die das Gegenteil einer monokausalen Bedeutung der Zell-DNA behaupten?
Die Entwicklungssystemtheorie ist nicht ganz so einfach zu widerlegen, denn sie bezieht sich auf sämtliche Zellsubstanzen, die im Jahre 1985 bekannt waren. Theoretisch müssten sämtliche Zellsubstanzen und ihr Einfluss auf alle Prozesse untersucht und bewertet werden, was natürlich praktisch unmöglich ist.
Darüber hinaus verneinen ihre Verfechter jede Kausalität. Die Frage nach Kausalität muss gar nicht mehr gestellt werden, da alles gleichmäßig von allem abhängt. Die Suche nach Ursachen von Zellprozessstörungen könnte an dieser Stelle abgebrochen werden.
Die Entwicklungssystemtheorie hat ähnliche Mängel wie ihre Antithese. Auch sie unterscheidet nicht zwischen der ursprünglichen Erbinformation und den späteren DNA als Transkriptionsvorlage. Sie berücksichtigt nicht die unterschiedliche Rolle von Faktoren und den restlichen Substanzen.
Auch nach gesundem Menschenverstand kann es keine absolute Gleichberechtigung aller Zellbestandteile geben. Es ist ein großer Unterschied, an welcher Stelle die Erbinformation beispielsweise einen Defekt aufweist. Ebenfalls spielen nicht alle zig-tausend Zellbestandteile die gleiche Rolle bei einer bestimmten Wirkung oder einem bestimmten Prozess. Warum sollten alle Proteine, die für spezielle Funktionen vorgesehen sind, andere Funktionen immer stören oder für deren Abläufe immer notwendig sein? Mit einer solchen Realität ist Leben, so wie es auf der Erde existiert, gar nicht zu vereinbaren, da die Organismen extrem anfällig wären. Hochkomplexe und funktionierende Lebewesen entstehen nur, wenn die Natur auf genügend Ausgleichsmechanismen zurückgreifen kann und es eben keine gleichwertige Abhängigkeiten aller Zellsubstanzen gibt.
Beide gegensätzlichen Ansichten helfen bei der Analyse von Kausalbeziehungen im unübersichtlichen Zellstoffwechsel nur weiter, indem man sie als Extrempositionen mit entsprechender Realitätsferne auffasst und daraus den Schluss zieht, dass die Wahrheit bzw. Synthese irgendwo in der Mitte liegen muss.
Wo diese Mitte liegt, wird im nächsten Abschnitt 3.2 bestimmt.
3.2 Das Postulat der Dominanz der Faktoren über die Zellprozesse ▲
Nachdem die Beschäftigung mit allgemeinen Erkenntnissen und speziellen Ansichten über Ursache-Wirkungs-Beziehungen noch keine befriedigenden Ergebnisse geliefert hat, sollte sich die Lösung bei einer genaueren Betrachtung des Zellprozessmodells ergeben, denn bei seiner Konstruktion ist auf eine exakte und ganzheitliche Darstellung aller grundlegenden Vorgänge geachtet worden.
Das Zellmodell kann auch als Funktionsgleichung dargestellt werden. Abläufe werden dort mit Hilfe von Peptiden (Enzyme, Proteine oder kurzkettige Peptide einschließlich der Monoamine) und acht Faktoren angetrieben. Zell‑DNA und mRNA befinden sich als zentrale Bestandteile des Hauptprozesses (= Proteinbiosynthese) auf der linken Seite einer solchen Gleichung. Haupt‑ und Folgeprozesse, einschließlich der Zell‑DNA‑Vorlage und der mRNA, sind demnach abhängig von Peptiden und acht Faktoren, was mittels einer einfachen Funktionsgleichung zum Ausdruck gebracht wird.
Hauptprozess (mit Zell-DNA und mRNA) & Nachfolgeprozesse =
f (Peptide + AS + uE + KL + MI + NF + ncRNA + O2 + H2O)
Legende Faktoren:
AS = Aminosäuren
uE = ursprüngliche Erbinformation
KL = Kohlenhydrate
MI = Mikronährstoffe
NF = Nahrungsfette einschließlich Fettbegleitstoffe
ncRNA = nicht-codierende Ribonukleinsäuren
O2 = molekularer Sauerstoff
H2O = Wasser
Zellmodell und Gleichung haben einiges mit der Ansicht der Entwicklungssystemtheoretiker gemein, jedoch gibt es sechs wesentliche Unterschiede:
- Die Gleichung macht keine Aussagen über die Wertigkeit bzw. Gleichwertigkeit der Bestandteile.
- Es wird unterschieden zwischen Erbinformation und prozesszugehöriger Zell‑DNA.
- Es wird zwischen Peptiden und Faktoren unterschieden.
- Es wird eine Abhängigkeit der Zell‑DNA und mRNA von Peptiden und Faktoren postuliert.
- Es werden von außen zugeführte Substanzen berücksichtigt.
- Die zu Oyamas Zeiten unbekannten ncRNA werden als Steuerungsfaktoren berücksichtigt.
Die Kongruënz von Prozessen mit Peptiden und Faktoren
Die Funktionsgleichung postuliert grundsätzliche Annahmen über Lebensprozesse. In der von ihr beschriebenen Realität entfalten sich sämtliche Zellprozesse mit Hilfe der aufgezählten neun Bestandteile bzw. Bestandteilgruppen automatisch: Peptide, Aminosäuren, ursprüngliche Erbinformation, Kohlenhydrate, Mikronährstoffe, Nahrungsfette/Fettbegleitstoffe, nicht-codierende Ribonukleinsäuren, Sauerstoff und Wasser. Ein „spezielles Programm“, vergleichbar mit einem zusätzlichen Projektmanagement, ist nicht notwendig.
Es kommt also nur auf die Anwesenheit der neun Bestandteile an, um die Funktionstüchtigkeit einer Zelle zu gewährleisten. Prozesse einschließlich DNA-Vorlage und mRNA auf der einen Seite und Peptide und Faktoren auf der anderen Seite sind damit kongruënt, das heißt identisch.
Der Grund für das scheinbar planmäßige Ineinandergreifen einer unvorstellbar großen Anzahl von Prozessen in jeder einzelnen Zelle aufgrund einer ebenfalls unvorstellbaren Anzahl vieler unterschiedlicher Bestandteile ist in seiner Gesamtheit nicht zu erklären und bleibt ein Mysterium. Es sollte hingenommen werden, dass Lebensprozesse automatisch beim Aufeinandertreffen dieser neun Substanzengruppen entstehen.
Als Verständnishilfe bietet sich die Vorstellung der „unsichtbaren Hand“ aus der Ökonomie an. Dieses Konzept besagt, dass sich Märkte durch unzählige Märkteteilnehmer von selber regeln. Etwas Vergleichbares geschieht in jeder Zelle. Ebenso kann von einer Schwarmintelligenz der Zellbestandteile gesprochen werden.
Faktoren dominieren Prozesse (Dominanzpostulat)
Im Kontext der Erklärung von Zellprozessstörungen kann man sich ab sofort auf die neun Bestandteile bzw. Bestandteilgruppen (Peptide, Faktoren) konzentrieren, die von ihrer Anzahl gesehen aber immer noch unvorstellbar groß sind und ‑ als wäre das noch nicht genug ‑ deren Funktionen häufig nicht oder nicht vollständig verstanden werden.
Wie kommt man jetzt voran, ohne in der Sackgasse einer erweiterten und differenzierteren „Entwicklungssystemtheorie der Entstehung von Zellerkrankungen“ stecken zu bleiben?
Kongruënzannahme und das Zellprozessmodell decken eine zweite Abhängigkeit auf. Die Peptid-Synthese beruht nämlich ausschließlich auf der Präsenz und dem Zusammenwirken von acht Faktoren, was folgende Funktionsgleichung ausdrückt:
Peptide = f (AS + uE + KL + MI + NF + ncRNA + O2 + H2O).
Mit der rechten Seite dieser Gleichung kann man jetzt die Ausgangsfunktion...
Hauptprozess (Zell-DNA, mRNA) & Nachfolgeprozesse =
f (Peptide + AS + uE + KL + MI + NF + ncRNA + O2 + H2O)
bedeutend vereinfachen, indem man Enzyme und Proteine durch diese rechte Seite ersetzt:
Hauptprozess (Zell-DNA, mRNA) & Nachfolgeprozesse =
F ( f [AS+uE+KL+MI+NF+ncRNA+O2+H2O] + AS + uE + KL + MI + NF + ncRNA + O2 + H2O).
Jetzt befinden sich auf der rechten Seite ausschließlich Faktoren, so dass diese verkürzt werden kann:
Hauptprozess (Zell-DNA, mRNA) & Nachfolgeprozesse =
f (AS + uE + KL + MI + NF + ncRNA + O2 + H2O)
...oder noch kürzer:
Prozesse (Zell-DNA, mRNA) = f (Acht Faktoren).
Das Streichen der Peptide lässt sich auch auf eine einfachere Weise darstellen, denn sie sind als Produkte des Hauptprozesses auch in der linken Funktionsgleichungsseite enthalten:
[Hauptprozess (Zell-DNA, mRNA) =
Peptide] & Nachfolgeprozesse =
f (Peptide+ AS + uE + KL + MI + NF + ncRNA + O2 + H2O) oder
Prozesse (Zell-DNA, mRNA) = f (Faktoren).
Die Gesamtheit der Enzyme und Proteine spielt bei der Suche nach Ursachen von Zellerkrankungen damit keine Rolle mehr, sie ist vernachlässigbar. Peptide sind zwar nach wie vor wichtig für einen funktionierenden Zellstoffwechsel, als Ursachen von Zellprozessstörungen sind sie in diesem Modell dennoch nur von sekundärer Bedeutung.
Die verkürzte Gleichung bringt die Dominanz der Faktoren über die Prozesse zum Ausdruck. Etwas ausführlicher formuliert lautet das Postulat:
Der reibungslose Ablauf aller Vorgänge in einer Zelle ist gewährleistet, wenn...
- die Erbinformation nach der Fertilisation (= Verschmelzung der mütterlichen und väterlichen Gene) ausreichend fehlerfrei und funktionsfähig ist,
- Aminosäuren, Kohlenhydrate, Mikronährstoffe, Nahrungsfette/Fettbegleitstoffe, Sauerstoff und Wasser in ausreichender Menge zur Verfügung stehen und
- nicht-codierende Ribonukleinsäuren in einem vom Hauptprozess separierten Parallelprozess korrekt synthetisiert werden.
Durch einfache Umkehrung lässt sich dann auch der Gegensatz dazu formulieren:
Zellprozessstörungen entstehen dann, wenn...
- die unmittelbar nach der Fertilisation entstandene Erbinformation Fehler aufweist und/oder
- Aminosäuren, Kohlenhydrate, Mikronährstoffe, Nahrungsfette/Fettbegleitstoffe, Sauerstoff und Wasser nicht in ausreichender Menge zur Verfügung stehen und/oder
- die Synthese nicht-codierender Ribonukleinsäuren gestört ist.
Kausalfaktoren als Begründer aller Zellvorgänge
Faktoren begründen den Zellstoffwechsel und ihre Mängel verantworten Zellstoffwechselstörungen. Aus diesen Gründen werden sie ab sofort als Kausalfaktoren bezeichnet. Die Zellprozessfunktionsgleichung lautet demnach:
Prozesse (Zell-DNA, mRNA) = f (Kausalfaktoren)
Abbildung 16 veranschaulicht ‑ stark vereinfacht ‑ diese Ursache-Wirkungs-Zusammenhänge.
ABBILDUNG 16: EIN KAUSALES MODELL DES ZELLSTOFFWECHSELS
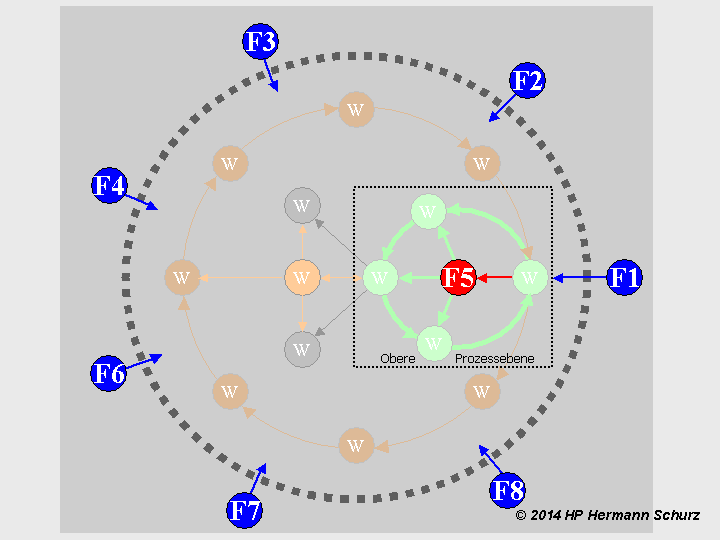
Abbildung 16: Innerhalb der gestrichelten Kreislinie (Zelle) sind Aussagen über Kausalzusammenhänge in Haupt- und Folgeprozessen nicht möglich, da jeder Wirkung (W) eine andere Wirkung vorausgeht und darüber hinaus zwei Kausalketten untereinander verschachtelt sind. Es liegen z. T. kreisförmige bzw. zyklische Kausalketten vor, wobei der grüne Kreislauf die Proteinbiosynthese darstellt, während der äußere braune Kreislauf die Zellteilung symbolisiert. Wenn es aber gelingt, bestimmte Bestandteile als Faktoren (F) zu identifizieren, die das Funktionieren des Systems von außen oder innen gemeinsam verantworten und steuern, führt das Fehlen oder die Dysfunktion eines oder mehrerer dieser Faktoren zu Prozessfehlern. Die Anwesenheit der Faktoren F1 bis F8 bzw. ihre fehlerlose Form ist grundlegend für das Funktionieren des Systems, sie sind Kausalfaktoren. Faktor 5 symbolisiert die innerhalb des Zellstoffwechsels synthetisierten nicht-codierenden Ribonukleinsäuren (ncRNA), deren Syntheseprozess (roter Pfeil) nicht Bestandteil des Hauptprozesses ist, sondern als unabhängiger Parallelprozess aufzufassen ist. Die nach ihrer Synthese stattfindenden Aktivitäten einzelner ncRNA gehören nichtsdestotrotz zur Transkription bzw. Translation, deshalb sind die dazugehörigen Symbolpfeile grün dargestellt.
Beispiel Industrieproduktion
Die Abhängigkeit der Zellprozesse von den dominierenden Kausalfaktoren lässt sich auch mit Hilfe eines industriellen Prozesses veranschaulichen (→ Abbildung 17), beispielsweise anhand der Produktion versandfertig verpackter Plastikflaschen.
Die Fabrik stellt ‑ analog zur Zelle ‑ ihre Produktionsmaschinen (dunkelgrün) selber her. Dies geschieht in anderen Unternehmensbereichen, die aus Gründen besserer Anschaulichkeit nicht dargestellt sind. Es handelt sich hier beispielsweise um Transportbänder, die Kühlanlage oder um andere produktionsbedingt notwendigen Mascheinen. Sie sind vergleichbar mit Enzymen oder Proteinen, die in der Zelle für den Proteinbiosyntheseprozess verantwortlich sind.
Die unfertigen Zwischenprodukte des zentralen Produktionsprozesses sind hellgrün dargestellt. Im Zellmodell entsprechen sie der DNA-Vorlage mit ihren Peptid-Genen und ncRNA-Codes (Pressvorlage, EDV-Konzept), der mRNA oder unmodifizierten Peptiden (nicht etikettierte Flaschen).
Mit den acht Kausalfaktoren der Zelle vergleichbar sind Elektrizität, Kunststoffgranulat, Kühlmittel, Etiketten, Klebstoff, Kartons, die EDV‑Steuerungseinheit und das Personal.
Sieben davon werden dem Betrieb von außen zugeführt: Elektrizität, Kunststoffgranulat, Kühlmittel, Etiketten, Klebstoff, Kartons und das Personal.
Die Prozesssteuerung erfolgt parallel in der EDV-Steuerungseinheit. Sie repräsentiert den achten Kausalfaktor und wird als einziger nicht von außen dem Produktionsprozess zugeführt. Die EDV-Steuerung ist als unternehmensinterner Prozess mit dem Herstellungsprozess nicht-codierender Ribonukleinsäuren vergleichbar.
Produktionsprobleme resultieren in diesem Modell ausschließlich aus Faktorproblemen. Sie sind immer Engpassprobleme.
Die Wirkungen auf den Produktionsprozess hängen von den Kausalfaktoren ab, bei denen es zum Engpass kommt. So unterbricht ein Stromausfall den Produktionsprozess und vielleicht auch sämtliche Prozesse in anderen Unternehmensbereichen, die mit der Herstellung der Produktionsmaschinen beschäftigt sind. Probleme in der EDV‑Steuerung führen ‑ je nach Situation ‑ zu verschiedenartigen Problemen bis hin zum kompletten Produktionsstillstand. Fehlen nur Etiketten, werden lediglich unetikettierte Flaschen produziert.
ABBILDUNG 17: PROZESSE UND FAKTOREN AM BEISPIEL DER INDUSTRIEPRODUKTION
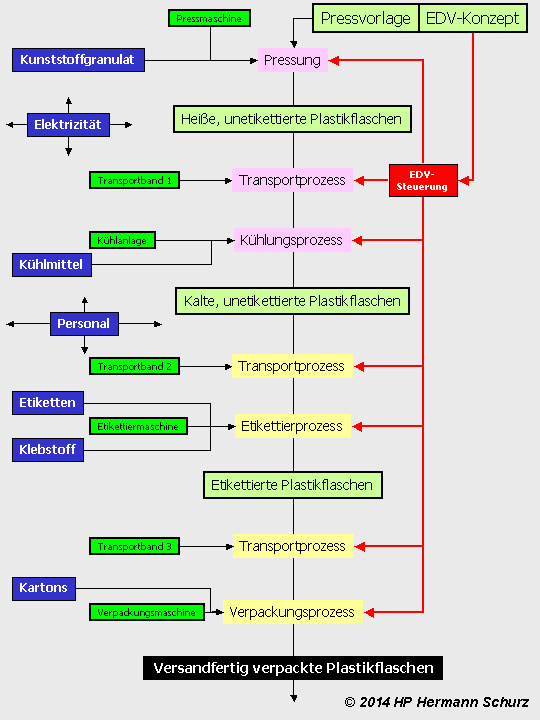
Abbildung 17: Das Zellprozessmodell mit seiner Trennung von Prozessen und Kausalfaktoren und die Dominanz der Faktoren über alle produzierenden Prozesse übertragen auf ein Beispiel aus der Industrie.
Spätestens jetzt fällt auf, dass das Modell noch lückenhaft ist. Zwar sind Kausalfaktorprobleme mit Sicherheit ein häufiger Grund für stockende Produktionsprozesse, in der Realität müssen jedoch auch Fehler berücksichtigt werden, die unmittelbar aus den Prozessen resultieren. Zum Beispiel kann der Transportprozess ins Stocken kommen, weil die Pressvorlage fehlerhaft ist oder das Transportband plötzlich nicht mehr funktioniert etc.
Das leitet über zum Abschnitt 3.3, denn übertragen auf das Zellprozessmodell muss es auch hier Gründe für Fehler geben, die nicht unmittelbar auf Enpassprobleme mit Kausalfaktoren zurückzuführen sind.
3.3 Nukleinsäureschäden und Reparaturprozesse ▲
Wie im vorhergehenden Abschnitt 3.2 gezeigt wurde, hat die Abhängigkeit der Haupt- und Folgeprozesse von Kausalfaktoren als Konsequenz, dass dysfunktionale Kausalfaktoren mit hoher Wahrscheinlichkeit zu Prozessstörungen führen. Kausalfaktoren sind somit auch Zellschwachstellen und das kommt in der Zellprozessfunktionsgleichung...
Prozesse (Zell-DNA, mRNA) = f (Kausalfaktoren)
zum Ausdruck.
Aber was ist mit der linken Seite der Funktionsgleichung, zu der die Nukleinsäuren Zell-DNA und mRNA gehören?
Wären Zell-DNA und mRNA völlig stabil und unverwüstlich, liefen alle Prozesse in dem von der Außenwelt isolierten Modell reibungslos ab bis zum „jüngsten Tag“, jedenfalls immer, solange ausreichende Mengen aller sieben stoffwechselaktiven Kausalfaktoren zur Verfügung stehen und die ursprüngliche Erbinformation als achter Kausalfaktor bei der Entstehung des Organismus fehlerfrei war.
Diese Sicht ist natürlich überaus unrealistisch, denn Nukleinsäureschäden gehören zum „Alltag“ einer Zelle und sind daher in einem multikausalen Modell zu berücksichtigen. Sie wurden nur aus Gründen einer verständlicheren Darstellung bisher außer Acht gelassen:
Prozesse (Zell-DNA, mRNA) = f (Kausalfaktoren).
Die Ursachen von Nukleinsäureschäden können sowohl fehlerhafte Codierungs‑ und Übertragungsprozesse von Zell‑DNA auf Zell‑DNA (DNA‑Replikation) oder von Zell‑DNA auf Boten‑RNA (Transkription) sein als auch davon unabhängige physiologische Vorgänge im Zellstoffwechsel.
Auch die Synthese einer Aminosäurenkette während der Translation ist fehleranfällig.
Um sich die Gefahren bewusst zu machen, denen Nukleinsäuren ständig ausgesetzt sind, reicht der Blick auf einen der Informationsübertragungsprozesse aus. So kopieren DNA-Polymerasen etwa 50 Nukleotide pro Sekunde während der DNA-Replikation (→ Abschnitt 2.2), teilweise an vielen Stellen parallel. Aufgrund von Prozesskomplexität und Schnelligkeit scheinen Fehler unvermeidbar. Animation 12 zeigt einen vereinfachten Replikationsprozess der DNA eines Bakteriums in Zeitlupe, der mit dem in menschlichen Zellen vom Prinzip her vergleichbar ist.
ANIMATION 12: DIE VERDOPPELUNG DER DNA VOR DER ZELLTEILUNG
Animation 12: Die Verdoppelung der DNA erfolgt beim Leitstrang kontinuierlich und beim Folgestrang diskontinuierlich, d. h. fragmentiert. Ein Helikase-Enzym ist dunkelblau dargestellt und entschraubt bzw. teilt den Doppelstrang in einen Leit- und einen Folgestrang (auf die Darstellung der Topiosomerase wurde verzichtet). Bei den hellblauen Strukturen in der Mitte an der Replikationsgabel handelt es sich um einen Multi-Enzymkomplex, der den ganzen Apparat zusammenhält, insbesondere die beiden violett dargestellten DNA-Polymerasen. Der Leitstrang wird kontinuierlich mit Hilfe einer DNA-Polymerase (Leading strand polymerase) verdoppelt. Der Folgestrang wird in der entgegengesetzten Richtung diskontinuierlich in Fragmenten (Okazaki fragment) mit einer anderen DNA-Polymerase verdoppelt (Lagging strand polymerase). Die sich unmittelbar neben den violetten DNA-Polymerasen befindenden grünen Clamp-Proteine haben eine Stabilisierungsfunktion. Bei den grüngrauen Proteinen, die immer wieder ins Bild kommen und sich hinter der Helikase am Folgestrang platzieren, handelt es sich um Primasen, die für die Synthese der Primer-RNA zuständig sind. Die Primer-RNA sieht man ganz kurz am Beginn jedes neuen Okazaki-Fragments (in gelber Farbe). Am Leitstrang werden keine Primasen (bzw. Primer-RNA) mehr benötigt, da die kontinuierliche Verdoppelung des Leitstrangs nur einen Primer zu Beginn erfordert, der hier nicht (mehr) zu sehen ist. Nicht so beim Folgestrang, da dort für jeden Beginn einer Fragmentsynthese eine Primer-RNA nowendig wird, so dass ständig grüngraue Primasen in den Komplex aufgenommen werden. Der graue Proteinkomplex in der Mitte sorgt dafür, dass die DNA‑Polymerase zusammen mit einem grünen Clamp-Protein für jede Fragmentsynthese korrekt am Folgestrang platziert wird. Später müssen die vielen Primer-RNA-Sequenzen zu Beginn jedes Fragments mit einem weiteren Enzym in DNA‑Sequenzen umgewandelt werden, was hier nicht gezeigt wird.
(Quelle: YouTube / DNA Learning Center, http://www.dnlac.org)
Noch einige Hinweise zum Verständnis:
- Nur Zell-DNA-Schäden, die sich dauerhaft nach Versagen der Reparaturmechanismen manifestiert haben, werden im Folgenden als Mutationen bezeichnet.
- Entstehungsmechanismen von Mutationen der ursprünglichen Erbinformation, beispielsweise während der Meiose, werden im Kapitel 3 nicht thematisiert. Hier handelt es ich um Keimbahnmutationen, die an die Nachkommen weitergegeben werden. Die ursprüngliche Erbinformation gehört zu den Kausalfaktoren und die Erörterung der Ursachen fehlerhafter Erbinformationen bzw. genetisch bedingter Erkrankungen erfolgt als Kausalfaktorproblem im Kapitel 4 (→ Abschnitt 4.7). Das betrifft auch die Konsequenzen, die durch Zusammenhänge zwischen der ursprünglichen Erbinformation und der ncRNA entstehen. Bei den hier erörterten Mutationen geht es ausschließlich um Mutationen der Zell-DNA, die auch als somatische Mutationen bezeichnet werden.
- Auch wenn nicht-codierende Ribonukleinsäuren (ncRNA) und ihre Rolle als Kausalfaktoren erst im Kapitel 4 thematisiert werden, ist es dennoch sinnvoll, Auswirkungen somatischer Mutationen auf ncRNA-Codes in der folgenden Übersicht zu erwähnen und in die Systematik mit einzubeziehen, um Redundanzen zu vermeiden. Denn die Mechanismen somatischer Mutationsprozesse sind identisch, gleich, ob es sich um Mutationen an Peptid-Genen oder an ncRNA-Codes handelt.
- Es geht bei den folgenden Themen nicht um Einzelheiten. Es genügt ein kurzer systematischer Überblick über die wichtigsten Gefahren, die Nukleinsäuren drohen und ihren Konsequenzen sowie den Möglichkeiten einer Zelle, sich mit verschiedenen Reparaturmöglichkeiten dagegen zu wehren.
- Zunächst werden Auslöser, Merkmale und Folgen von Zell-DNA- oder RNA-Schäden beschrieben, danach wird in den Abschnitten 3.3.1 bis 3.3.6 ein Überblick über Schadenstrategien und Reparaturmechanismen gegeben. Die Inhalte dieser Abschnitte sind für das Gesamtverständnis von untergeordneter Bedeutung. Wer an diesen Details nicht interessiert ist, sollte jetzt oder spätestens am Ende dieser einleitenden Übersicht beim Abschnitt 3.3.7 weiterlesen.
Fehlprozesse als Ursachen von Schäden an Nukleinsäuren und Aminosäurenketten
Zunächst ist es sinnvoll, die gesamte Prozesskette einschließlich der ncRNA-Synthese systematisch nach potentiellen Fehlerquellen für Nukleinsäuren abzusuchen.
An der Zell-DNA kann es während der beiden Informationsübertragungsprozesse Replikation und Transkription zu Schäden kommen.
Eine weitere Schadenquelle sind spontane Zell-DNA-Schäden, die nicht im Zusammenhang mit Informationsübertragungsprozessen stehen und jederzeit eintreten können. Derartige spontane DNA-Schäden lassen sich in zwei Gruppen differenzieren: in natürlich-induzierte und exogen-induzierte DNA-Schäden.
Natürlich-induzierte Zell-DNA-Schäden geschehen spontan und ohne erkennbaren Grund oder aufgrund unvermeidbarer Noxen von außen. Darunter gehören beispielsweise die natürliche Zellatmung mit ihren schädigenden reaktiven Sauerstoff-Spezies oder die natürliche Radioaktivität.
Nicht natürliche Exogen-induzierte Zell-DNA-Schäden werden durch zusätzliche Noxenbelastung von außen provoziert, die prinzipiell vermeidbar sind. Das können radioaktive Strahlen sein, die über die natürliche vorhandene Menge hinausgehen, Gifte oder Kranheitserreger usf.
Eine exakte Abgrenzung zwischen natürlich‑induzierten und nicht natürlichen exogen‑induzierten Zell‑DNA‑Schäden ist nicht in jedem Falle möglich oder sinnvoll. Alternativ kann daher auch zwischen physiologisch‑spontanen DNA‑Schäden unbekannter Ursache und Noxen‑induzierten DNA‑Schäden unterschieden werden, bei letzteren dann unabhängig davon, ob Noxen natürlichen oder nicht natürlichen Ursprungs sind, da die Schadenmechanismen sich nicht voneinander unterscheiden.
Nicht nur bei der Zell‑DNA, auch bei der ncRNA und der Boten‑RNA kann es während der Informationsübertragungsprozesse zu Fehlern in der Basenabfolge kommen. Sie entstehen während der Transkription oder während des Processings bzw. bei der Boten‑RNA auch während des Spleißens.
Eine weitere Quelle von Informationsübertragungsfehlern sind fehlbeladene tRNA und Fehler während der Translation beim Ablesen der mRNA. Hier sind ausschließlich Aminosäurenketten direkt betroffen.
Nachfolgend zusammenfassend eine systematische Übersicht der Ursachen von Schäden an der Zell-DNA, mRNA, ncRNA und an Aminosäurenketten, die in der folgenden Abbildung 18 visualisiert ist.
- Ursachen von Schäden der Zell-DNA
1.1 Die DNA-Replikation vor der Zellkernteilung verläuft fehlerhaft (replikationsbedingte DNA-Schäden).
1.2 DNA-Schäden aufgrund der Transkription (transkriptionsbedingte DNA-Schäden).
1.3 Physiologische DNA-Spontanschäden unbekannter Ursachen.
1.4 Durch Noxen induzierte DNA-Schäden*.
Aus nicht reparierten DNA-Schäden resultieren somatische Mutationen, die später entweder fehlcodierte mRNA bzw. fehlcodierte ncRNA zur Folge haben können oder deren Synthese ggf. vollständig verhindert wird. Das kann wiederum fehlerhafte Aminosäurenketten oder eine falsche Anzahl von ihnen zur Folge haben (keine, zu wenig, zu viel).
* Es werden physikalische Noxen (z. B. ionisierende Strahlen), chemische Noxen (z. B. Mangel an Mikro- oder Makronährstoffen, reaktive Sauerstoff-Spezies ROS oder Toxine) und biologisch-medizinische Noxen (z. B. Viren) unterschieden (→ Kapitel 4, Teile A und B).
- Direkte Ursachen fehlerhafter ncRNA
Auch ncRNA können direkt geschädigt werden:
2.1 Ablese- bzw. Übertragungsfehler während der ncRNA-Synthese.
2.2 Fehler während des ncRNA-Processings.
- Direkte Ursachen fehlcodierter mRNA
Auch mRNA können direkt geschädigt werden:
3.1 Ablese- bzw. Übertragungsfehler während der mRNA-Synthese.
3.2 Fehler während des mRNA-Processings oder des Spleißens.
- Direkte Ursachen von Schäden an Aminosäurenketten
Auch wenn bis zur Translation alles störungsfrei abgelaufen ist, kann es auch jetzt noch aus zwei Gründen zu fehlerhaften Aminosäurenketten kommen:
4.1 Durch fehlbeladene tRNA werden „falsche“ Aminosäuren in die Kette eingebaut.
4.2 Übersetzungsfehler während der Translation durch falsch abgelesene mRNA.
ABBILDUNG 18: URSACHEN FEHLERHAFTER NUKLEINSÄURENKETTEN
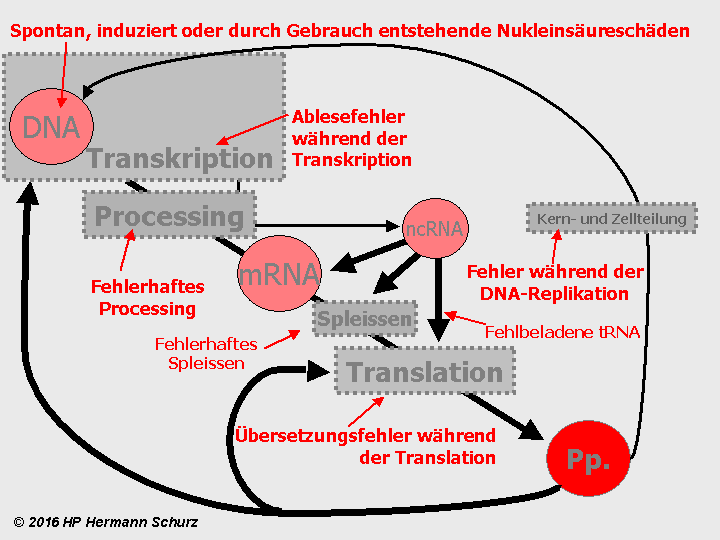
Abbildung 18: Bei jeder Informationsübertragung oder Informationsveränderung sind Fehler möglich. Die Zell-DNA ist darüber hinaus auch durch spontane oder induzierte Ereignisse gefährdet, zum Beispiel durch natürlichen oxidativen oder nitrosativen Stress. Auch ständige Ableseprozesse können zu Schäden an der DNA-Vorlage führen. Die Schäden betreffen sowohl Peptid-Gene als auch ncRNA-Codes. Die Endergebnisse sind im ungünstigsten Fall fehlerhafte, fehlende oder zu viele Peptide (Pp.), denn sie stehen ganz am Ende der Synthesekette als Produkte der Proteinbiosynthese.
Verschiedene Arten von Schäden bei Nukleinsäuren und Aminosäurenketten
Die beschriebenen Fehlprozesse haben verschiedene Konsequenzen für DNA, ncRNA, mRNA oder Aminosäurenketten:
- Replikationsbedingte Schädigungen der Zell-DNA
1.1 Substitution = DNA-Basen/-Nukleotide nicht komplementär zum Partner (Mismatch, → Animation 13).
1.2 Deletion = DNA-Basen bzw. -Nukleotide fehlen.
1.3 Insertion = Überflüssige DNA-Basen bzw. -Nukleotide werden eingefügt.
Hier können einzelne (= Punktmutation) oder mehrere Basen bzw. Nukleotide betroffen sein.
- Spontane oder noxeninduzierte Schädigungen der Zell-DNA
2.1 Basenoxidation = Basenatome geben Elektronen an reaktive Substanzen ab, z. B. an freie Radikale.
2.2 Desaminierung = Fehlerhafte Basenpaarungen aufgrund chemischer Veränderungen an der DNA.
2.3 Depurinierung = Die Purinbasen Adenin und Guanin werden vom DNA-Gerüst abgespalten.
2.4 Depyrimidinierung = Wie Depurinierung, jedoch mit den Pyrimidinbasen Cytosin und Thymin.
2.5 Brüche von Chromosomen ohne weitere Veränderungen an der Chromosomenstruktur.
2.6 Brüche von Chromosomen mit der Folge diverser Chromosomenstrukturveränderungen.
- Transkriptions- oder processingbedingte Fehlcodierungen von ncRNA bzw. mRNA
3.1 RNA-Basen oder -Nukleotide passen nicht zu ihren komplementären DNA-Basen.
3.2 RNA-Basen oder -Nukleotide fehlen an vorgesehenen Stellen.
3.3 RNA-Basen oder -Nukleotide sind an Stellen eingefügt, an denen sie nicht vorgesehen sind.
3.4 Die ncRNA ist fehlerhaft aufgrund von Problemen beim ncRNA-Processing.
3.5 Fehlende Cap-Struktur oder fehlerhafte Poly-A-Sequenz nach fehlerhaftem mRNA-Processing
3.6 mRNA-Fehler aufgrund von Fehlern während des Spleißens.
- Translationsbedingte Fehler an Aminosäurenketten
4.1 Aminosäuren werden nicht entsprechend der mRNA-Vorlage in die Kette eingebaut.
4.2 Aminosäuren fehlen an vorgesehenen Stellen.
4.3 Es werden überflüssige Aminosäuren eingefügt.
Auswirkungen somatischer Zell-DNA-Mutationen auf Aminosäurenketten
Von allen Veränderungen der Nukleinsäuren sind alleine DNA-Mutationen relevant. Nur sie haben das Potential, sich langfristig im Zellstoffwechsel zu etablieren und auf Tochterzellen übertragen zu werden.
DNA-Mutationen haben nicht immer negative Konsequenzen. Es werden drei Möglichkeiten unterschieden:
- DNA-Mutationen haben keine Auswirkungen auf die spätere Aminosäurenprimärstruktur und deren Aminosäurenabfolge ist unverändert. Das wird auch als „stille Mutation“ bezeichnet. Beispielsweise können redundante Basencodes, die gemeinsam den gleichen Aminosäurentyp codieren, für stille Mutationen verantwortlich sein (→ Abschnitt 2.2). Weitere Erklärungen dazu folgen im nächsten Abschnitt.
Aus einer unveränderten Aminosärenprimärstruktur sollte bei korrekter Faltung eine unveränderte dreidimensionale Aminosäurensekundärstruktur resultieren.
- DNA-Mutationen haben strukturell-qualitative Auswirkungen auf die Primärstruktur der Aminosäurenkette, da Aminosäuren fehlbesetzt sind.
Fehlbesetzte Aminosäurenketten haben jedoch nicht automatisch Veränderungen der Sekundärstruktur zur Folge. Die Sekundärstruktur kann sogar unverändert oder in verschiedenen Abstufungen (Qualitäten) verändert sein. Sind Aminosäureabweichungen nur gering oder treten sie an funktionsunkritischen Stellen des späteren Peptids auf, ist die Sekundärstruktur manchmal sogar unverändert oder die Veränderung ist so gering oder unbedeutend, dass die Funktionalität der Sekundärstruktur vollständig gewährleistet ist.
Oft sind aber Funktionseinschränkungen unausweichlich. Sie reichen von nur sehr geringen bis zu massiven Fehlfunktionen oder kompletter Funktionslosigkeit. Je nachdem, an welchem Prozess das fehlerhafte Peptid beteiligt ist, kann das zum Zelltod führen. Im schlechtesten Fall ist das Ergebnis eine (Krebs-)Zelle.
Sind Peptide von strukturell-qualitativen Veränderungen betroffen, die genregulatorische Funktionen haben, beispielsweise Transkriptionsfaktoren, wirkt sich das potentiell genregulatorisch-quantitativ aus. Das leitet über zum nächsten Punkt 3.
- DNA-Mutationen haben genregulatorisch-quantitative Auswirkungen auf die Anzahl produzierter Aminosäurenketten. Es werden drei Unterformen differenziert:
3.1 ist ein Sonderfall von der unter 2. genannten Konsequenz, denn strukturell-qualitative Schäden genregulatorisch relevanter Peptide, beispielsweise Transkriptionsfaktoren oder Histone, haben Auswirkungen auf die Anzahl der Peptide, an deren Regulation sie beteiligt sind. Das Gleiche gilt für Peptide, die mit ncRNA-Molekülen zusammenarbeiten, beispielsweise Argonauten- oder RISC-Proteine. Die Konsequenzen reichen von einer übermäßigen Produktion bis hin zu einem völligen Produktionsausfall.
3.2 Mit der unter 3.1 beschriebenen Konsequenz sind Schäden an ncRNA‑Codes vergleichbar, die für die Synthese und Regulation der Peptide mitverantwortlich sind. Auch hier läuft die Genregulation aus dem Ruder. Sind einzelne ncRNA-Moleküle für viele mRNA verantwortlich, kann das erhebliche Folgen für eine Vielzahl von Peptiden haben.
3.3 Dieser Fall betrifft Codierungsfehler an Promotor- oder Enhancer-Regionen der DNA, welche die Transkription behindern oder sogar unmöglich machen.
Mit dieser Aufzählung ist der Überblick über Schäden an Nukleinsäuren und Aminosäurenketten abgeschlossen. In den folgenden Abschnitten 3.3.1 bis 3.3.6 werden Repaturprozesse vorgestellt. Wer daran nicht interessiert ist, sollte bei Abschnitt 3.3.7 weiterlesen.
3.3.1 Mutationsvermeidungsstrategien durch Fehlertoleranz, Fehlervermeidung und Zelltod
Somatische DNA-Mutationen werden bei jeder DNA-Replikation auch an Tochterzellen weitergegeben und verändern dauerhaft die DNA aller nachfolgenden Zellgenerationen. Aufgrund ihrer Gefährlichkeit hält die Natur ein ganzes Bündel von Fehlervermeidungsstrategien und Reparturmaßnahmen bereit, um DNA-Mutationen oder deren Auswirkungen möglichst gering zu halten.
Im Abschnitt 3.3.1 werden verschiedene Fehlervermeidungsstrategien vorgestellt. Es ist für eine Zelle besser, Fehler von vornherein zu vermeiden, anstatt später aufwändige Reparaturprozesse durchführen zu müssen.
Man unterscheidet drei Strategien, Fehler von vornherein zu vermeiden: Fehlertoleranz, Fehlervermeidung und den Zelltod. Schon hiermit wird erreicht, dass die Fehlerquote im ersten Replikationsdurchgang nur etwa 10 hoch -5 Fehler pro Basenpaar beträgt.
Fehlertoleranz wird durch redundante Basencodes und die Nutzung von Introns erzielt, Fehlervermeidung durch Besonderheiten der Polymerasentätigkeit. Eine sehr bedeutende und für den Organismus hochgefährliche DNA-Mutation wird idealerweise mittels Zelltod beseitigt.
- Redundante Basencodes: Für 20 Aminosäuren stehen 64 Codierungsmöglichkeiten zur Verfügung, die alle genutzt werden (→ Abschnitt 2.3). Dabei korreliert die Häufigkeit der Codons für eine Aminosäure mit der Häufigkeit ihres Vorkommens in den Peptiden. Aminosäuren, die viel verwendet werden, haben somit mehr Codierungsmöglichkeiten als selten eingesetzte Aminosäuren. Die wenig verwendeten Aminosäuren Tryptophan oder Methionin sind durch jeweils nur ein einziges Codon repräsentiert, während die häufig verwendeten Aminosäuren Serin oder Leucin jeweils durch sechs Codons redundant codiert werden. Ebenfalls unterscheiden sich die Synonyme oft nur durch eine der drei Basen. Beides führt dazu, dass kleinere Mutationen auf der Zell-DNA häufig keine Folgen für die spätere Aminosäurensequenz haben. Folgenlose Mutationen werden als stille Mutationen bezeichnet.
Redundante Basencodes haben aber noch einen weiteren Vorzug für die spätere Transkription, denn die Gefahr von Transkriptionsabbrüchen wäre sehr hoch, wenn jede Aminosäure nur durch ein Codon repräsentiert ist. Denn dann gäbe es viele codierungsfreie Sequenzen, die unweigerlich zum Abbruch oder der Unterbrechung einer Transkription führen würden mit wesentlich höheren Risiken für den Organismus. Dagegen ist der Einbau einer falschen Base für die spätere Aminosäurenkette häufig folgenlos, zum Beispiel wegen des schon erwähnten redundanten Basencodes oder einer unwichtigen Aminosäurenposition auf der Kette.
- Introns als Orte für Fehlcodierungen:
Die DNA überträgt an die unreife mRNA auch funktionslose Introns, die später beim Spleißen herausgeschnitten werden (→ Abschnitte 2.3.1 und 3.3.5). Es besteht eine hohe Wahrscheinlichkeit, dass eine Mutation dort lokalisiert ist und damit automatisch beseitigt wird. Eine Mutation innerhalb der Intron-Sequenzen ist ebenfalls eine stille Mutation.
- Induced-Fit-Prinzip: DNA‑Polymerasen passen sich während der Informationsübertragung in ihrer aktiven Mitte räumlich den korrekten Nukleotidpaarungen an, so dass der Einbau eines nichtkomplementären Nukleotids stark erschwert bis fast unmöglich gemacht wird (Schlüssel‑Schloss‑Prinzip). Vor allem diesem Mechanismus ist die relativ niedrige Brutto-Fehlerquote von 10 hoch ‑5 im ersten Durchgang einer Replikation zu verdanken. Ähnliches gilt übrigens auch für die RNA-Polymerasen während der Transkritpion.
- Apoptose-Mechanismus: Bestimmte Enzyme bzw. Proteine, beispielsweise p53 oder Caspasen, lösen einen gewünschten Zelltod bei gefährlichen DNA-Mutationen aus, die ansonsten mit fatalen Konsequenzen für den Gesamtorganismus verbunden wären, zum Beispiel einer Karzinom-Gefahr. Aufgrund dieser Funktion wird das p53-Protein auch als Wächter-Protein bezeichnet.
3.3.2 Reparaturen an der Zell-DNA während oder kurz nach der Replikation
Haben alle Vermeidungsstrategien nichts genutzt und sind replikationsbedingt Fehler aufgetreten, verfügt die Zelle über mehrere Reparatursysteme, mit deren Hilfe sie Fehler noch während der Replikation oder sofort danach „ausbügelt“.
Bei der komplizierten DNA-Replikation treten Schäden naturgemäß häufiger auf (→ Animation 12). Trotzdem ist die Fehlerquote nach Abschluss der Chromosomenverdoppelung außerordentlich gering. Sie beträgt nur 10 hoch -10 bis 10 hoch -9 Fehler pro Basenpaar, was der spontanen Mutationsrate entspricht.
Die Replikationsfehlerquote vor der Reparatur ist daher ungleich höher: Die DNA-Polymerasen synthetisieren die DNA-Tochterstränge mit 10 hoch -5 bis 10 hoch -4 Fehlern pro Basenpaar. Auch wenn diese Quote auf den ersten Blick immer noch niedrig erscheint, würden damit im Lauf der Zeit zu viele nicht kontrollierbare Mutationen durch Fehleranhäufung (Akkumulation) die Folge sein. Die nachfolgend beschriebenen Reparaturmechanismen sind geeignet, diese Fehler zu beseitigen.
- Proofreading: Diese erste Stufe, zu Deutsch „Korrekturlesen“, erfolgt sofort durch die replizierende DNA-Polymerase parallel zum Replikationsprozess. Bevor sie das nächste Nukleotid einsetzt, überprüft sie das gerade eingesetzte auf Kompatibilität zum Partnernukleotid der Vorlage. Stimmen die beiden nicht überein, stoppt sie die Replikation und löst die Bindung, so dass das fehlbesetzte Nukleotid freigesetzt wird und wiederholt die Replikation. Über Proofreading-Funktionen verfügen die DNA‑Polymerasen delta und eta.
- Mismatch-Reparatur (→ nachfolgende Animation 13): Eine Basenfehlpaarungsreparatur findet unmittelbar nach den einzelnen Replikationen statt, so dass die Arbeit der DNA-Polymerase nochmals überprüft und ggf. korrigiert wird. Der Mechanismus erkennt nichtpassende Basen, schneidet sie heraus und setzt die passende Basen ein. Dabei werden in der Regel mehrere Basen rund um die fehlerhafte(n) Base(n) beseitigt und anschließend korrigiert. Der Mismatch-Mechanismus ist entscheidend, denn er ist hauptsächlich für die sehr niedrige Mutationsrate nach einer Replikation verantwortlich. Durch ihn wird die Fehlerquote nach dem Proofreading nochmal etwa um das 1.000fache (!) gesenkt.
Für diese Reparatur sind beim Menschen acht verschiedene Reparaturproteine bekannt: Msh2 bis Msh6, Mlh1, Mlh3, PMS2 und vor allem die für den Abbau der fehlerhaften Basen zuständige Exonuklease (EXO1).
Die Mismatch-Reparatur ist nicht auf replikationsbedingte Basenschäden begrenzt (→ Abschnitt 3.3.3).
- Rekombinations-Reparatur: Dieser Mechanismus, auch als postreplikative Reparatur bezeichnet, wird ausgelöst, wenn eine DNA-Replikation abgebrochen und an einer entfernteren Stelle des DNA-Strangs wieder aufgenommen wird.
Gründe für die Unterbrechung sind Fehler auf dem DNA-Vorlagestrang, aufgrund derer die DNA-Polymerase ab dieser Stelle nicht mehr ablesen kann oder eine fehlerhaft arbeitende DNA-Polymerase. Der DNA-Strang wird daher an einer nachfolgenden Stelle weiter repliziert, so dass der Prozess auf jeden Fall zu Ende gebracht wird.
Jedoch liegt nun ein unvollständiger Doppelstrang vor, dem an eben jener Stelle Nukleotide fehlen. Es ist im Gegensatz zum Replikationsabbruch jedoch das kleinere Übel, denn die Lücke kann durch eine speziell dafür vorgesehene DNA-Polymerase und eine DNA-Ligase wieder geschlossen werden.
Die Rekombinations-Reparatur betrifft den fehlreplizierten Tochterstrang und beseitigt natürlich nicht den ursprünglichen Fehler am Mutterstrang, falls hier die Ursache des Abbruchs liegt. Sollte die Reparatur nicht gelingen, besteht immer noch die Möglichkeit, dass Apoptose-Proteine zur Tat schreiten und den Zelltod auslösen.
Die für einen Replikationsabbruch verantwortlichen DNA-Fehler entstehen häufig auch spontan oder werden durch Noxen ausgelöst. Der Reparaturprozess für diesen Fall wird im Abschnitt 3.3.3 beschrieben.
- p53-Unterbrechungsmechanismus: Hierbei handelt es sich nicht um ein eigenständiges Reparatursystem, sondern um einen notwendigen Hilfsprozess. Mit Hilfe des Proteins p53 sorgt die Zelle für eine notwendige Unterbrechung der Replikation im Falle eines Fehlers. Dadurch ist es überhaupt erst möglich, den Korrekturprozess durchzuführen. Das Protein hat also ‑ neben der Apoptose ‑ noch andere Funktionen.
3.3.3 Reparaturen nach spontanen oder noxeninduzierten Schäden der Zell-DNA
Weitere Reparaturmechanismen sind ständig aktiv und kümmern sich vor allem um DNA-Schäden, die spontan auftreten oder durch Noxen ausgelöst werden und nicht während eines Informationsübertragungsprozesses geschehen.
Allein spontane Depurinierungen verursachen pro Tag und Zelle einen Verlust von etwa 5.000 der Purinbasen Adenin bzw. Guanin, bei den spontanen Desaminierungen der restlichen Basen wird die Zahl auf mehrere hundert Schäden pro Tag und Zelle geschätzt.
Nichtsdestotrotz
besteht die Möglichkeit, auch replikationsbedingte Fehler nachträglich mit Hilfe dieser Prozesse zu korrigieren, denn die Zell-DNA wird ständig nach fehlerhaften Stellen abgesucht und die Schadenursache hat dabei keine Bedeutung. Dazu kommt es aber äußerst selten, da der Replikationsprozess aufgrund der in Abschnitt 3.3.2 beschriebenen Repaturmechanismen schon mit einer hohen Genauigkeit abläuft. Trotzdem es ist von Vorteil, wenn mehrere Reparaturmechanismen miteinander konkurrieren bzw. sich ergänzen.
Umgekehrt gilt das daher genauso, denn die Mismatch-Reparatur, die hauptsächlich für die Beseitigung replikationsbedingter Fehler vorgesehen ist, kann genauso bei spontanen oder induzierten Schäden angewendet werden und ähnelt darüber hinaus dem nachfolgend beschriebenen BER-Mechanismus.
- Exzisions-Reparaturprozesse: Verschiedene Mechanismen erkennen DNA-Schäden und sorgen anschließend für deren Korrektur.
Die Reparaturprozesse bestehen jeweils aus drei Teilen. Zunächst wird eine schadhafte Stelle anhand von DNA-Doppelhelix-Strukturverzerrungen mit Hilfe darauf spezialisierter Peptide identifiziert. Diese lösen den Reparaturmechanismus aus, die fehlerhafte Stelle wird entfernt und anschließend korrigiert.
Man unterscheidet die Basen-Exzisions-Reparatur (BER) und die Nukleotid-Exzisions-Reparatur (NER). Letztere wiederum wird mit der Globalen Genom-Reparatur (GGR) und der Transkriptionsgekoppelten DNA-Reparatur (TCR) in zwei Unterkategorien geteilt.
Bei der BER werden kleinere Basenschäden, beispielsweise desaminierte oder oxidativ geschädigte Basen, mittels DNA-Glykosylase-Enzymen (z. B. APE1, OGG1) lokalisiert und danach von drei anderen Enzymen bzw. Proteinen korrigiert.
Nach der Identifikation erfolgt ein Schnitt des DNA-Rückgrats mit einer Endonuklease, dann werden die geschädigte Base und die Nukleotidreste entfernt. In diese freie Stelle wird dann ein neues Nukleotid eingefügt. Diese Vorgänge erledigt die DNA‑Polymerase beta mit Hilfe des Enzyms XRCC1. Die DNA‑Ligase I bzw. DNA‑Ligase III verknüpft die Nukleotide wieder miteinander.
Größere Basenschäden und Einzelstrangbrüche werden mit Hilfe des NER‑Reparaturmechanismus beseitigt. Die großen Veränderungen an der DNA-Doppelhelixstruktur können nur mit einem höheren Reparaturaufwand beseitigt werden, dazu ist die BER nicht geeignet. Für die NER sind viele Peptide nötig. Beim Menschen werden allein 30 verschiedene Polypeptide mit der NER in Verbindung gebracht, nachfolgend werden einige davon genannt.
Nach der Defekterkennung durch einen speziellen Multi-Proteinkomplex schneiden zwei Endonukleasen (ERCC1, ERCC2) ein etwa 25 bis 32 Nukleotide langes Oligonukleotid rund um den Defekt heraus, danach reparieren die DNA-Polymerase delta und DNA-Polymerase eta mit den korrekten Basenpaarungen die Lücke. Anschließend sorgt eine DNA-Ligase IV dafür, dass die korrigierten Nukleotide miteinander verkettet werden.
In humanen Zellen existieren zwei verschiedene Unterkategorien des NER-Mechanismus, die sich aber nur in der Art des Anlasses der Schadenerkennung und der dazu nötigen Erkennungsprozesse unterscheiden. So ist die GGR (Globale Genom-Reparatur) die Bezeichnung für einen Prozess, bei dem ständig nach größeren DNA-Strukturfehlern in transkriptionsrelevanten, aber gerade inaktiven Bereichen abgesucht und repariert wird, während die TCR (Transkriptionsgekoppelte DNA-Reparatur) bei laufender Transkription Fehler erkennt und repariert. Dadurch sind auch unterschiedliche Proteine für die Erkennung notwendig. Bei der GGR wird das durch den Proteinkomplex XPC-HHR23B erledigt, während bei der TCR zunächst die RNA-Polymerase mittels Enzymen entfernt werden muss, damit die TCR-Proteine überhaupt zur schadhaften Stelle Zugang bekommen. Die sich anschließenden Korrekturprozesse sind bei der GGR und TCR identisch.
- DNA-Reparatur durch homologe Rekombination (HR): Sind beide Stränge eines DNA-Doppelstrangs gebrochen, kann die Reparatur mit Hilfe des unbeschädigt gebliebenen identischen Chromosoms erfolgen, denn mit Ausnahme des Geschlechtschromosoms liegt jedes Chromosom in einem doppelten Satz vor („Schwesterchromosom“). Ein Doppelstrangbruch gehört zu den schwersten DNA-Schäden, der unrepariert mit hoher Wahrscheinlichkeit mit dem Zelltod endet.
Da Doppelstrangbrüche meist noxeninduziert sind, werden die dazugehörigen Reparaturprozesse hier in Abschnitt 3.3.3 beschrieben. Jedoch ist anzumerken, dass es auch bei der DNA-Replikation zu derartigen Schäden kommen kann, zum Beispiel beim Zusammenbruch der Replikationsgabel, was aber eher selten vorkommt (→ Animation 12).
Die Reparatur ist, im Gegensatz zur Reparatur von Einzelstrangbrüchen, ein sehr komplizierter Vorgang (Einzelstrangbrüche werden mit der oben beschriebenen Nukleotid-Exzisions-Reparatur repariert). Zunächst müssen die identischen Stellen auf dem Schwesterchromosom gefunden werden. Anschließend werden die Enden der beiden gebrochenen Einzelstränge mit den jeweils identischen (homologen) Bereichen des intakten Doppelstrangs in Kontakt gebracht, die dadurch als Reparaturvorlage dienen. Durch die HR ist nicht garantiert, dass der reparierte DNA-Doppelstrang fehlerfrei ist, jedoch gelingt es dem Prozess meist, die genetische Information zu bewahren.
Es werden mehrere Modelle der HR diskutiert, was hier aber nicht weiter von Bedeutung ist. An diesem Prozess ist eine große Anzahl von Proteinen beteiligt, zum Beispiel Kohäsine, NBX, MRE11, RAD50, BRCA1 oder BRCA2.
- DNA-Reparatur durch nicht-homologe End-zu-End-Verknüpfung (NHEV): Dieser Mechanismus ist die Alternative zur HR. Er verzichtet auf die komplexe Interaktion mit dem Schwesterchromosom und verknüpft einfach die Enden der beiden gebrochenen Einzelstränge miteinander. Dabei wird ein möglicherweise entstehender DNA-Fehler in Kauf genommen. Die NHEV ist dennoch die wichtigere Reparaturalternative in Säugetierzellen, sie wird also beim Menschen weit häufiger angewendet als die HR – im Gegensatz zu Bakterien, bei denen es genau umgekehrt ist. An diesem Prozess sind verschiedene Exonukleasen und die DNA-Ligase IV beteiligt.
Warum dieser Reparaturvorgang bei Säugtieren der HR vorgezogen wird, ist noch nicht eindeutig geklärt. Es wird vermutet, dass es aufgrund der komplexeren Strukturen der Chromosomen und deren hoher Zahl in tierischen Zellen bei der komplizierten HR zu mehr Fehlern kommen würde, aus denen schwerwiegende Mutationen resultieren. So scheint die NHEV die bessere Alternative bzw. das kleinere Übel zu sein.
ANIMATION 13: MISMATCH-REPARATUR
Animation 13: Eine stark vereinfachte Darstellung des wichtigen Mismatch-Reparaturmechanismus nach einem Fehler während der DNA-Replikation, Erklärung siehe oben in Abschnitt 3.3.2 unter Punkt 2. Top strand steht hier für Leitstrang, Bottom strand für Folgestrang, unten links entstehen diskontinuierlich die Okazaki-Fragmente am Folgestrang. Es wird auf die Bedeutung des EXO1-Proteins verwiesen, das für die Entfernung des Replikationsfehlers (Mismatch) zuständig ist. Die Animation zeigt die Replikation selbst allerdings mit zwei Ungenauigkeiten. Das Aufbrechen in Einzelstränge erfolgt real mittels eines Helikase-Enzyms und es gibt für die beiden Einzelstränge auch zwei unterschiedliche Polymerasen. Auch entsteht leider der Eindruck, als ob der obere DNA-Strang die Polymerase unbearbeitet durchläuft.
(Quelle: YouTube / Howard Hughes Medical Institute, http://www.hhmi.org)
3.3.4 Fehlervermeidung und Reparatur transkriptionsbedingter Übertragungsfehler auf der mRNA
Auch während des Transkriptionsvorgangs der Proteinbiosynthese kommt es naturgemäß zu Fehlern bei der Informationsübertragung auf mRNA und ncRNA.
Führt man sich die Schnelligkeit des Transkriptionsprozesses vor Augen (→ Animationen 1 bis 3, Abschnitt 2.2.1), wird dessen Fehleranfälligkeit verständlich. Die Transkriptionsfehlerrate ist wesentlich höher als die der DNA‑Replikation.
Transkriptionsbedingte Übertragungsfehler auf die RNA sind für die Zelle jedoch weniger problematisch als DNA-Replikationsschäden, denn nur letztere werden an Tochterzellen weitergegeben.
Fehlcodierte mRNA sind zwar nicht so gefährlich, sie dürfen dennoch nur in einem vertretbaren Maße entstehen. Keinesfalls darf der Transkriptionsprozess derart schludrig ablaufen, dass Übertragungsfehler übermäßig auftreten. Um eine ausreichend niedrige Transkriptionsfehlerquote zu erzielen, kommen auch hier verschiedene Strategien bzw. Mechanismen zum Einsatz: Fehlertoleranz, Fehlervermeidung und Reparaturprozesse.
RNA-Polymerasen führen diese Reparaturprozesse durch. Sie sind mit weniger Aufwand verbunden als jene, die bei der wichtigen DNA-Replikation angewendet werden. Eine Zelle wird bei transkriptionsbedingten Übertragungsfehlern ihre Ressourcen nicht verschwenden und nur in angemessener Weise reparieren. So führen RNA-Polymerasen beispielsweise den Proofreading-Mechanismus nicht durch, der bei der DNA-Replikation obligatorisch angewendet wird. Scheinbar ist dieser zu aufwändig. Nachfolgend eine Aufzählung der bekannten Strategien und Mechanismen.
- Fehlertoleranz, Fehlervermeidungsstrategien und Abbau fehlerhafter RNA
Hier gibt es Ähnlichkeiten mit dem DNA-Replikationsprozess, so dass die Vorgänge nur kurz erwähnt werden.
Redundante Basencodes: Vom Vorteil redundanter Basencodes profitiert natürlich auch die Transkription (→ Abschnitt 3.3.1), denn so werden trotz Mutationen der Zell-DNA die „richtigen“ Basen transkribiert.
Redundante Basencodes haben aber gerade bei der Transkriptionen noch einen weiteren Vorzug, der oben schon erwähnt wurde. Die Gefahr von Transkriptionsabbrüchen wäre sehr hoch, wenn jede Aminosäure nur durch ein Codon repräsentiert ist. Denn dann gäbe es viele codierungsfreie Sequenzen, die unweigerlich zum Abbruch oder der Unterbrechung einer Transkription führen würden mit wesentlich höheren Risiken für den Organismus. Dagegen ist der Einbau einer falschen Base für die spätere Aminosäurenkette häufig folgenlos, zum Beispiel wegen des schon erwähnten redundanten Codes oder der Aminosäurenposition auf der Kette.
Induced-Fit-Prinzip: Auch die RNA-Polymerase nutzt dieses Prinzip (→ Abschnitt 3.3.1).
Befreiung steckengebliebener RNA-Polymerasen: Das Enzym kann sich während des Transkriptionsprozesses verhaken, so dass die Transkription stoppt. Dafür muss nicht unbedingt ein Fehler der RNA-Polymerase vorliegen, der unfreiwillige Stopp kann auch ohne nachvollziehbaren Grund geschehen. Dieses Malheur wird durch ein TRCP-Protein behoben, das sich entlang des DNA-Vorlagestrangs in Richtung der RNA-Polymerase vorschraubt und diese durch den Zusammenstoß wieder dazu bringt, die Transkription fortzusetzen. Alternativ wird sie durch den Zusammenstoß von der DNA abgespalten, so dass eine neue RNA-Polymerase die Transkription an derselben Stelle fortsetzt.
Introns als Ort für Fehlcodierungen: Werden Introns mit dem Processing beseitigt, gilt das logischerweise auch für Fehler, die sich auf diesen Introns befinden. Jeder vorab betriebene Fehlerbeseitigungsaufwand auf Introns wäre damit verschwendete Energie (→ Abschnitt 3.3.5).
Abbau fehlcodierter mRNA: Ein paar fehlcodierte unreife RNA sind auch aufgrund ihrer raschen Zerfallszeit nicht besonders gefährlich. Ob fehlerhafte RNA von der Zelle gezielt gesucht und durch Nukleasen eliminiert werden, ist nicht nachgewiesen, allerdings auch nicht das Gegenteil. Hier könnten micro‑RNA eine Rolle spielen (→ Abschnitt 2.2.3).
- Reparaturen während und nach der Transkription
Auch hier ist der Reparaturaufwand entsprechend der geringeren Gefährlichkeit einzelner fehlcodierter RNA angemessen und nicht vergleichbar mit den Reparaturprozessen, die für die Fehlerbehebung an der Zell-DNA während und nach der Replikation aufgewendet werden.
Pyrophosphorolytische Editierung (PE): Die RNA-Polymerase erkennt, entfernt und ersetzt falsch eingesetzte Nukleotide sofort.
Hydrolytische Editierung (HE): Die fehlerhaften Nukleotide werden mittels „Back tracking“ ausgetauscht, das heißt, die RNA-Polymerase wandert ein bis zwei Nukleotide zurück, spaltet das unpassende Nukleotid oder die Fehlsequenz ab und wiederholt die Transkription.
Exkurs: Transkriptionsbedingte Abnutzungsschäden der Zell-DNA
Bevor nun das Spleißen näher betrachtet wird, soll noch auf einen die DNA betreffenden Aspekt des Transkriptionsvorgangs verwiesen werden.
Das Trennen der DNA-Doppelstränge, das anschließende Auslesen der DNA und das Zusammenführen der beiden getrennten Stränge am Ende des Vorgangs ist ein aufwändiger Prozess, der auf der DNA im Laufe der Zeit mit hoher Wahrscheinlichkeit Abnutzungsschäden zur Folge hat.
Schon bestehende DNA-Fehler, die während der Transkription durch den TCR-Mechanismus entdeckt und repariert werden, sind hier nicht gemeint (→ Abschnitt 3.3.3).
Die Zelle wird versuchen, derartige transkriptionsbedingte Schäden wahrscheinlich durch einen Mix aus den in den Abschnitten 3.3.2 und 3.3.3 dargestellten Mechanismen zu beseitigen. Hier könnte der TCR-Mechanismus vielleicht auch eine größere Rolle spielen.
Leider sind hier die wissenschaftlichen Erkenntnisse fast gleich Null. Aber gerade transkriptionsverursachte DNA-Schäden helfen dabei, zelluläre Erschöpfungseffekte besser zu verstehen. Wenn eine Zelle von einer bestimmten Substanz aufgrund einer normabweichenden Situation über längere Zeit viel produzieren muss, kann eine sich anschließende Produktionserschöpfung auch mit Abnutzungsschäden am betreffenden DNA-Gen erklärbar sein, die von den Reparaturmechanismen nicht beseitigt werden konnten.
3.3.5 Die Bedeutung des Spleißens im Falle von Fehlern oder Schäden an der mRNA
Das Spleißen, also das Herausschneiden von Basensequenzen aus der gerade entstehenden Boten‑RNA, die scheinbar keine Informationen für das Peptid enthalten, ist ein hochkomplexer Vorgang, der noch nicht richtig verstanden wird. Diese Basensequenzen werden auch Introns genannt, im Gegensatz zu den informativen Exons.
Es scheint so, als ob jede mRNA auf verschiedene Arten gespleißt werden kann. Das wird als alternatives Spleißen bezeichnet und bedeutet, die Intron- und Exonelemente wie verschiebbare Bausteine abweichend vom ursprünglichen Plan zu (re-)kombinieren, woraus dann unterschiedliche Peptide resultieren.
Nach der Entdeckung dieses Prinzips ist die bis dahin geltende Ein-Gen-ein-Peptid-Hypothese ins Wanken geraten. Man ging nämlich bis dahin davon aus, dass ein Gen immer nur ein bestimmtes Peptid codiert. Durch alternatives Spleißen ist eine Zelle aber in der Lage, aus einem Gen mehrere unterschiedliche Peptide zu konstruieren. Es wird teilweise die Meinung vertreten, dass gezielt alternatives Spleißen nicht nur das Codierungspotential der DNA wesentlich erhöht, sondern auch ein wichtiger Motor der Evolution ist, denn es entstehen auf diese Weise auch neue, nützliche Proteine.
Fehlerhaftes Spleißen kann auch erblich bedingt sein. Dabei wird der Spleißvorgang nicht korrekt durchgeführt, so dass eine bestimmte mRNA ausschließlich fehlerhaft wird. Entweder wird dann die Herstellung des Peptids unmöglich gemacht oder es entstehen zellschädigende Proteine.
Für sonstige Fehler, die einer Zelle während des Spleißvorgangs unterlaufen können, gilt das Gleiche wie für Fehler während der Transkription: Sie sind aufgrund ihres sporadischen Auftretens eher unproblematisch, dennoch muss der Prozess geordnet ablaufen, damit ein gewisses Maß an Qualität gewahrt bleibt. Dass das nicht so einfach ist, wird duch Animation 14 klar.
ANIMATION 14: SPLEISSEN (SPLICING)
Animation 14: Das Beispiel zeigt die Tätigkeit der Spleißosomen genannten Protein-Komplexe. Schon während der Transkription werden die grün dargestellten Introns aus der unreifen mRNA herausgeschnitten und die Enden der Exons miteinander verkettet. Ein menschliches Gen hat im Schnitt ca. 6 bis 7 Exons und 5 bis 6 Introns.
(Quelle: YouTube / DNA Learning Center, http://www.dnlac.org)
Derzeit geht man von mindestens einem Mechanismus aus, mit dem die Zelle den Spleißvorgang überprüft. Demnach werden die zu trennenden Intron-Exon-Übergänge von einer speziellen ncRNA-Sorte, den snRNA, erkannt. Nach Trennung und Verkettung prüft das Spleißosom, ein aus verschiedenen Proteinen bestehender Komplex, mit Hilfe der snRNA nochmal an den zusammengefügten Stellen nach, ob auch wirklich korrekt gespleißt wurde, erst dann wird der Prozess fortgesetzt. Es ist nicht klar, ob es einen Reparaturmechanismus gibt oder welche Konsequenzen ein sporadisch fehlerhaftes Spleißen hat. So könnte der Prozess einfach abbrechen und die mRNA bleibt inaktiv bis zum Abbau durch Nukleasen.
Die snRNA (Small nuclear ribonucleic acid) haben eine Länge von bis zu 300 Nukleotiden. snRNA werden mittels der RNA-Polymerasen II und III synthetisiert. Es gibt in tierischen Zellen eine hohe Anzahl von snRNA, sie wird auf 10 hoch 6 pro Zelle geschätzt. Insgesamt sind bisher 24 snRNA-Typen bekannt.
Das Spleißen ist zur Beseitigung von Fehlcodierungen auf der Boten‑RNA aus folgenden Gründen relevant:
- Befinden sich Schäden auf einem Intron, werden sie beim Spleißen automatisch entfernt.
- Da während des Spleißprozesses auf der mRNA bestimmte Markierungen zwischen den Exons durch Exon-Junction-Proteine hinterlassen werden, kann die Zelle im Regelfall bei der späteren Translation unsinnige Fehlsequenzen in der Form vorzeitiger Stopcodons identifizieren und daraufhin die fehlerhafte Boten‑RNA mit Exonukleasen abbauen. Dieser Kontrollmechanismus wird als Nonsense‑mediated mRNA decay (NMD) bezeichnet, der jedoch Teil der Translastion ist.
3.3.6 Fehlervermeidung und Reparatur translationsbedingter Übertragungsfehler
Translationsfehler sind bezüglich des Gefahrenpotentials mit denen der Transkription vergleichbar und damit für die Zelle verhältnismäßig gut zu verkraften. Die Kenntnisse über die Ribosomentätigkeit sind noch nicht ausreichend, man ist derzeit Mechanismen lediglich auf der Spur, die für eine Genauigkeit des Prozesses sorgen.
Auch bei der Translation wirkt sich die Redundanz des Basencodes positiv aus und reduziert Fehlübersetzungen bzw. vorzeitige Abbrüche (→ Abschnitt 3.3.1).
Das oben schon erwähnte Erkennen überflüssiger Stoppcodierungen an der mRNA mit Hilfe von Exon-Junction-Proteinen und anschließendem Stopp der Translation und Abbau durch Exonukleasen zählt auch zu den translationsbedingten Fehlervermeidungsstrategien.
Das Ribosom verfügt darüber hinaus über einen speziellen Induced-Fit-Mechanismus, der Fehlpaarungen zwischen dem Codon der mRNA und dem Anticodon der Transfer-RNA verhindert.
Ebenso gibt es ein Proofreading durch die Ribosomen, so dass nicht passende Transfer-RNA so gut wie keine Chance haben.
Es wird aktuell ein Reparaturprozess erforscht, bei dem fehlende Stopp-Markierungen während der Translation ergänzt werden.
Die korrekte Beladung der Transfer-RNA mit den passenden Aminosäuren ist ebenfalls ein wichtiger Teilaspekt der Translationskontrolle, und auch hier gibt es Mechanismen, die einen Fehlbesatz fast unmöglich machen sollen.
Ein fehlerhaftes, unbrauchbares Protein provoziert meist sofort seinen Abbau durch Proteasom-Proteine, so dass die Aminosäuren dem Stoffwechsel wieder zur Verfügung stehen und das Protein keinen Schaden anrichtet. Mit Hilfe des Markierungsproteins Ubiquitin und weiterer Proteine (zum Beispiel Ubiquitin‑Ligasen) erkennt die Zelle beschädigte Proteine und beginnt den Wiederverwertungsprozess. Dabei ist es natürlich wiederum unerheblich, an welcher Stelle der Proteinbiosynthese der Fehler seine Ursache hat.
3.3.7 Das um Prüf- und Reparaturmechanismen erweiterte Zellmodell
Prüf- und Reparaturprozesse müssen nun noch in das Zellprozessmodell integriert werden (→ Abbildung 13). Das fällt nicht schwer, denn deren Charakteristika stimmen mit sämtlichen anderen Prozessen überein, so dass sich in der Darstellung Wesentliches ändert:
- Prüf- und Reparaturprozesse entfalten sich automatisch, wenn eine Zelle die dazu nötigen Enzyme und Proteine mittels Proteinbiosynthese herstellen kann. Damit ist die Proteinbiosynthese als vorgelagerter Prozessbestandteil ein Bestandteil aller Prüf- und Reparaturprozesse.
- Acht Kausalfaktoren in korrekten Form und notwendigen Vielfalt bestimmen als notwendige Substanzen aller Abläufe ebenfalls die Qualität der Prüf- und Reparaturprozesse.
- Prüfung und Reparatur gehören elementar sowohl zum Proteinbiosyntheseprozess als auch zur Kern- und Zellteilung, so dass ihre Darstellung in einer weiteren Prozessgruppe entbehrlich ist. Die Modellgraphik muss deshalb noch nicht einmal um einen fünften Prozesskomplex erweitert werden; die schon bestehenden Beschreibungen in den rechteckigen grünen Feldern unten werden lediglich ergänzt. Lediglich die Beschreibung der einzelnen Prozessschritte P1 bis P12 werden beispielhaft um einige Prüf- und Reparaturpeptide erweitert.
Das Zellmodell wird formal um diese Prozesse ergänzt, an den Abläufen ändert sich nichts Grundsätzliches. Die für das mRNA-Processing wichtigen snRNA sollten in der ergänzten Modellgraphik ebenfalls nicht fehlen.
ABBILDUNG 19: DAS UM PRÜF- UND REPARATURPROZESSE ERWEITERTE ZELLPROZESSMODELL
Abbildung 19: Das Zellprozessmodell verweist nun auch auf die Peptide und Prozesse zur Prüfung und Reparatur beider Nukleinsäuren Zell-DNA und mRNA, obwohl diese in der vorhergehenden Modell-Graphik schon impliziert waren. Die snRNA als wichtige Substanzen des Spleißprozesses sind jetzt dargestellt. Sämtliche Prinzipien des Modells bleiben unverändert. Die Proteinbiosynthese bleibt vorgelagerter Hauptprozess aller nachfolgenden Zellprozesse und Kausalfaktoren dominieren die Prozesse.
Hier noch einmal die aus Kapitel 2 bekannte Auswahl von Enzymen und Proteinen in den einzelnen Prozessschritten P1 bis P12, ergänzt durch diejenigen, die für Prüf- und Reparaturprozesse notwendig und fett hervorgehoben sind:
- PS 1 durch Aktivatoren, Helikasen, Repressor-Proteine, RITS-Proteine, RNA-Polymerase II, Histone oder Transkriptionsfaktoren.
- PS 2 durch RNA-Polymerasen I, II oder III und TRCP.
- PS 3 durch Nukleasen, TBP, TRCP oder TREX.
- PS 4 durch Cleavage-Faktoren, Exon-Junction-Proteine, Nukleasen, PolyA-Polymerasen und Spleißosome.
- PS 5 durch Dicer-Enzyme, Exportin 5 und Nukleasen.
- PS 6 durch Argonautenproteine, Nukleasen oder RISC-Proteine.
- PS 7 durch Argonautenproteine, EF-G, EF-Ts, EF-Tu, eRF1 bis eRF3, iF1 bis iF11, Peptidyltransferasen, Proteasome, Ribosomen, RISC-Proteine, Ubiquitin und Ubiquitin-Ligasen.
- PS 8 durch Chaperone, Chaperonine (Chaperonzylinder) und Transportproteine.
- PS 9 durch Diversifizierungsenzyme, Motor- und Transportproteine (z. B. SRP oder MPP) oder Zellorganellen (z. B. Endoplasmatisches Retikulum).
- PS 10 durch DNA-Polymerasen alpha, Helikasen, Histone, Primasen und Topiosomerasen.
- PS 11 durch DNA-Polymerasen alpha, beta, delta oder eta, DNA-Ligasen, EXO1, Helikasen, Histone, Mlh1, Mlh3, Msh 2 bis Msh 6, p53, PM2, Primasen, RNasen H, Topiosomerasen und Tus.
- PS 12 durch BRCA1, BRCA2, DNA-Glykosylasen, DNA-Ligasen I, III oder IV, DNA‑Polymerasen beta, delta oder eta, Endonukleasen, Kohäsine, Membranproteine, Motorproteine, MRE11, NBX, RAD50, TCR‑Proteine, XPC‑HHR23B und XRCC1.
- PS 13 durch verschiedenen Enzyme und Proteine, die induzierte und physiologische Mutationen reparieren.
3.3.8 Relevanz von Mutationen der Zell-DNA
Nachdem die Bedeutung der Reparaturmechanismen und deren Integration in das Zellprozessmodell geklärt sind, muss nun noch geprüft werden, welche Relevanz somatische DNA-Mutationen haben.
Es ist ja nicht so, dass Fehlervermeidungsstrategien und Reparaturprozesse gemeinsam in der Lage sind, die Anzahl der DNA-Mutationen auf Null zu reduzieren. In der Realität werden diese lediglich minimiert, stellen aber weiter eine Gefahr dar. Daher können sie auch in einem um Reparaturvorgänge erweiterten Prozessmodell nicht ignoriert werden.
Die Frage ist aber, wie diese Integration erfolgt. Sind DNA-Mutationen mit dysfunktionalen Kausalfaktoren vergleichbar und repräsentieren damit einen neunten Kausalfaktor? Oder ist deren Charakteristik eine ganz andere, zum Beispiel eine den Kausalfaktoren unter- oder übergeordnete? Behalten die Kausalfaktoren ihre dominante Rolle auch gegenüber den DNA-Mutationen oder nicht?
Die Erörterung folgender drei Aspekte soll bei der Beantwortung der Frage helfen:
- Wie unterscheiden sich somatische DNA-Mutationen und fehlerhafte Kausalfaktoren voneinander?
- Hängen somatische DNA-Mutationen von Kausalfaktoren ab?
- Welche sonstigen Abhängigkeiten gibt es zwischen somatischen DNA-Mutationen und (dysfunktionalen) Kausalfaktoren?
Aspekt 1: Unterschiede zwischen somatischen DNA-Mutationen und fehlerhaften Kausalfaktoren
Zwischen einer DNA-Mutation und einem dysfunktionalen Kausalfaktor gibt es erhebliche Unterschiede:
- Kausalfaktoren sind stofflich definiert. DNA-Mutationen stellen keine Substanzen dar, sie sind lediglich ein Zustand der Zell-DNA.
- Die Zell-DNA dient als Vorlage für die Transkription und ist damit ein prozesszugehöriger Bestandteil der Proteinbiosynthese (linke Seite der Prozessfunktionsgleichung). Kausalfaktoren sind Substanzen, welche die Proteinbiosynthese überhaupt erst ermöglichen (rechte Seite der Prozessfunktionsgleichung).
Die Kausalfaktoren übernehmen eine Rolle als Antreiber des Zellstoffwechsels. Eine solche Funktion hat die DNA aus den genannten Gründen nicht.
Aspekt 2: Hängen somatische DNA-Mutationen von Kausalfaktoren ab?
Anzahl und Charakter der DNA-Mutationen hängen maßgeblich von der Funktionsfähigkeit der DNA-Reparturprozesse ab, DNA-Reparaturprozesse werden wiederum von Kausalfaktoren bestimmt.
Der Grund dafür ist das Dominanzpostulat, dem auch DNA-Fehlervermeidung und DNA-Reparaturprozesse als ganz normale Zellabläufe unterliegen (→ Abschnitt 3.2). Das kommt in der speziellen Zellprozessfunktionsgleichung...
Reparaturprozesse (Zell-DNA, mRNA) = f (AS, uE, KL, MI, NF, ncRNA, O2, H2O)
zum Ausdruck.
Aspekt 3: Sonstige Abhängigkeiten zwischen Kausalfaktoren und somatischen DNA-Mutationen?
Es gibt auch den umgekehrten Fall der Abhängigkeit eines Kausalfaktors von somatischen DNA-Mutationen. Hier handelt es sich um die auf der Zell-DNA codierten ncRNA, denn auch ncRNA-Codes können mutieren. Diese wechselseitige Abhängigkeit kommt in der modifizierten Funktionsgleichung...
Prozesse (Zell-DNA, mRNA) = F [AS, uE, KL, MI, NF, ncRNA (Zell-DNA), O2, H2O]
zum Audruck.
In Abbildung 20 werden alle drei Aspekte visualisiert.
ABBILDUNG 20: ABHÄNGIGKEITEN ZWISCHEN SOMATISCHEN MUTATIONEN UND KAUSALFAKTOREN
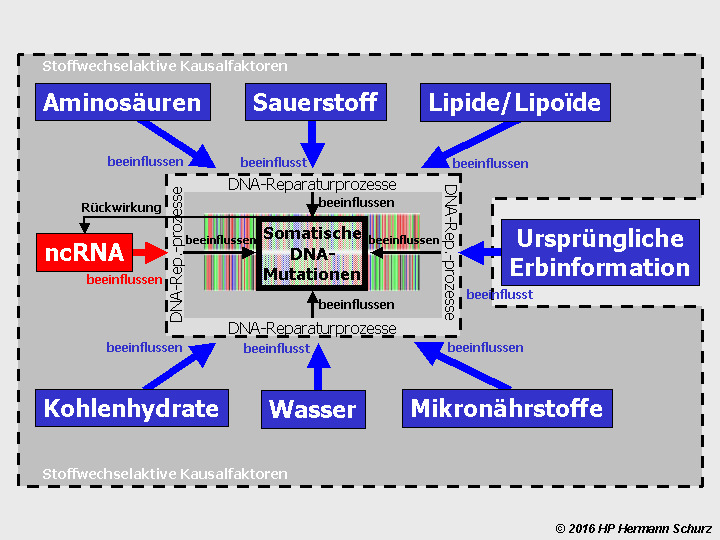
Abbildung 20: Qualität und Quantität somatischer DNA-Mutationen sind von sieben stoffwechselaktiven Kausalfaktoren und der ursprünglichen Erbinformation abhängig, denn sie garantieren und beeinflussen die Funktionsfähigkeit der DNA-Reparaturprozesse. Nicht-codierende Ribonukleinsäuren (ncRNA) sind die einzigen Kausalfaktoren, die wiederum von diesen Mutationen direkt beeinflusst werden, denn somatische Mutationen verändern auch ncRNA-Codes (schwarzer Pfeil „Rückwirkung“). Eine wechselseitige Abhängigkeit gibt es nur zwischen ncRNA und DNA-Mutationen.
Die Zell-DNA stellt eine von acht Kausalfaktoren dominierte neunte Zellschwachstelle dar
Die Tatsache, dass auch die DNA-Reparaturprozesse von der Anwesenheit und den Aktivitäten der Kausalfaktoren abhängig sind, impliziert eine Ursache-Wirkungs-Beziehung zwischen Kausalfaktoren und der Existenz von DNA-Mutationen: Quantität und Qualität somatischer Mutationen sind von Kausalfaktoren abhängig, die weiterhin die dominierenden Elemente des Zellmodells bleiben.
Darüber hinaus sind somatische DNA-Mutationen - im Gegensatz zu dysfunktionalen Kausalfaktoren - keine Substanzen. Sie stellen lediglich einen Zustand auf der DNA dar. Sie sind auch keine „Treiber“ des Zellstoffwechsels. Diese Rolle übernehmen ausschließlich Kausalfaktoren.
Kausalfaktoren bleiben damit weiterhin die dominierenden Elemente des Zellmodells. Das Postulat der Dominanz der Faktoren über alle Zellprozesse als zentrale Aussage bleibt unverändert bestehen.
DNA-Mutationen sind aber nicht vollständig vermeidbar. Das kann auch eine perfekt abgestimmte Zusammenarbeit aller Kausalfaktoren nicht leisten; diese garantiert lediglich, dass Anzahl und Schwere von Mutationen minimiert werden.
Die Bedeutung somatischer DNA-Mutationen als weiteres Zellproblem steigt noch durch den Umstand, dass auch Gene nicht-codierender RNA von ihnen betroffen sein können: ncRNA und DNA-Mutationen sind wechselseitig voneinander abhängig.
Im Zellmodell müssen DNA-Mutationen deshalb als Gefahr wahrgenommen werden, auch wenn sie aus den genannten Gründen keine mit Kausalfaktoren vergleichbare Bedeutung haben: Das Potential somatischer Mutationen bzw. die Zell-DNA stellt eine neunte Zellschwachstelle dar, deren Einflüsse bei Analysen von Erkrankungsursachen zu berücksichtigen sind.
3.3.9 Die Verbindung von Zellprozessmodell und 3-Stufen-Modell
Zellprozessmodell und Dominanzpostulat implizieren den Beginn einer degenerativen Entwicklung durch dysfunktionale Kausalfaktoren, die folgendermaßen verläuft:
Dysfunktionale Kausalfaktoren → Zellprozessstörungen → Zellfunktionsstörungen
Diese Entwicklung hat ‑ wie beim 3-Stufen-Modell ‑ drei Stufen, wobei die letzte Stufe der Zellfunktionsstörungen mit der ersten Stufe des 3-Stufen-Modells identisch ist.
Kombiniert man Zellprozessmodell und 3-Stufen-Modell miteinander, ist das Ergebnis eine fünfstufige Kausalkette, welche die Folgen dysfunktionaler Kausalfaktoren für endogene Zellprozesse als auch für externe Zellaktivitäten zeigt.
Abbildung 21 zeigt diese Entwicklung. Dysfunktionale Kausalfaktoren bzw. Kausalfaktorprobleme (Stufe 1) führen zu Prozessfehlern (Stufe 2) und diese wiederum zu Funktionsstörungen der Nerven- und Gliazellen (Stufe 3). Mittel- bis langfristig kann daraus ein Rückgang der Nervenzellvernetzung resultieren (Stufe 4), der im Abbau/Absterben von Nerven- oder Gliazellen enden kann (Stufe 5).
ABBILDUNG 21: DIE VERBINDUNG VON ZELLPROZESSMODELL UND 3-STUFEN-MODELL
Abbildung 21: Das geschlossene Zellmodell einschließlich des Dominanzpostulats erklären kausale Zusammenhänge innerhalb des Zellstoffwechsels, die Kausaltheorie postuliert, welche Konsequenzen das anschließend für die Reizverarbeitungsaktivitäten der Zelle haben kann. Die gesamte Kausalkette hat fünf Stufen.
3.4 Ein Vergleich zellphysiologischer Relevanzen von Kausalfaktoren ▲
Das wichtige Ergebnis aller bisherigen Analysen in Kapitel 3 ist daher:
Zellstörungen beruhen ‑ trotz Gefahren somatischer Mutationen ‑ vor allem auf Kausalfaktormängeln
Das bedeutet jedoch immer noch eine hohe Zahl potentieller Prozessstörer, denn alleine vier Kausalfaktoren bestehen aus vielen bis fast unzähligen Teilfaktoren, es handelt sich eigentlich um Kausalfaktorgruppen: Aminosäuren, die ursprüngliche Erbinformation, Mikronährstoffe und nicht-codierende Ribonukleinsäuren.
Allein die Anzahl der Mikronährstoffe ist groß, wie aus der kurzen Übersicht des Abschnitts 2.4 hervorgeht. Dabei wurde auf die Darstellung der vielen sekundären Pflanzenstoffe sogar verzichtet. Dagegen ist die Gruppe der Aminosäuren mit nur 20 Substanzen noch relativ übersichtlich.
Micro‑RNA und andere ncRNA‑Moleküle sind in jeder Zelle in einer unvorstellbaren Vielfalt und Zahl vorhanden. Dazu kommt die komplexe Erbinformation mit ihrer Vielfalt von Gen‑ und ncRNA‑Codes. Das Wissen über diese beiden Kausalfaktoren ist darüber hinaus sehr gering, die Bedeutung vieler ncRNA‑Moleküle ist derzeit noch rätselhaft und auch über die Einflüsse der Erbinformation ist erst die sprichwörtliche Spitze des Eisbergs bekannt.
Dazu kommt noch die Tatsache, dass es einen starken Zusammenhang zwischen Erbinformation bzw. Zell-DNA und ncRNA gibt, denn ncRNA-Moleküle sind auf der DNA codiert. Unter Kausalitätsaspekten kann es daher keine strikte Trennung zwischen Erbinformation und somatischen Mutationen auf der einen und ncRNA-Molekülen auf der anderen Seite geben, wie schon Abbildung 20 nahelegt (→ Abschnitt 3.3.8), was eine vergleichende Kausalfaktorenbewertung verkompliziert.
Einige Faktoren sind so wichtig, dass ihr Fehlen innerhalb weniger Tage den Zelltod herbeiführen würde (Wasser), beim Fehlen von Sauerstoff sogar innerhalb weniger Minuten ‑ insbesondere im Zentralnervensystem. Dennoch wird niemandem Wasser oder Sauerstoff als den entscheidenden Kausalfaktoren im Zusammenhang mit einer Zellerkrankung im Allgemeinen bzw. einer Nervenerkrankung im Besonderen einfallen. Oder sind Wasser bzw. Sauerstoff viel stärker an der Genese von Erkrankungen beteiligt und wurden ihre Rollen bisher nur unterschätzt? Hat beispielsweise Sauerstoff nun eine ganz hohe Relevanz, eine ganz niedrige oder liegt dessen Bedeutung eher in der Mitte? Und wie ist die Relevanz des Sauerstoffs im Vergleich zu anderen Kausalfaktoren zu bewerten?
Es scheint, als sei die Erkenntnis der Dominanz von acht Kausalfaktoren bzw. Kausalfaktorgruppen lediglich ein minimaler Fortschritt. Im nächsten Schritt müssen daher Rolle und Bedeutung der Kausalfaktoren näher bestimmt werden einschließlich des Versuchs, eine Rangfolge ihrer Bedeutung als potentielle Zellprozessstörer im Falle von Mängeln zu definieren.
Zunächst ist zu klären, ob bei einer außerordentlich großen Anzahl potentieller Ursachen in einem geschlossenen System grundsätzlich belastbare Aussagen über Kausalzusammenhänge gemacht werden können. Dazu muss man sich mit dem Kausalitätsbegriff intensiver auseinandersetzen, als es zu Beginn dieses Kapitels geschah.
3.4.1 Bijektive vs. surjektive kausale Spezifität
Bei einem idealen oder strengen Kausalzusammenhang liegt immer eine bijektive kausale Spezifität vor, auch als Eineindeutigkeit bezeichnet. Das gilt für die Ereignisse 3/4 bzw. 5/6 in Abbildung 14 oben oder die Ereignisse 1/2 bzw. 3/4 in der folgenden Abbildung 22 unten. Hier hat ein Auslöser nur eine Wirkung, so dass ein eindeutiger Schluss von einem Ereignis auf die Wirkung und auch umgekehrt der eindeutige Rückschluss von der Wirkung auf ein Ereignis möglich sind.
Kommen mehrere Ereignisse für eine Wirkung in Frage ‑ und das ist in den Naturwissenschaften fast immer der Fall ‑ ist dieses Konzept unbrauchbar, denn es lässt sich eine Wirkung in der Regel eben nicht auf ein einziges Ereignis zurückführen. Die kausale Spezifität ist dennoch erfüllt, wenn die Anzahl der Ereignisse, die für eine Wirkung verantwortlich sind, auf eine überschaubare Menge begrenzt werden kann. Dieser Sachverhalt wird surjektive kausale Spezifität genannt. Es liegt zwar keine Eineindeutigkeit, wohl aber Eindeutigkeit vor.
Bis zu welcher Menge an Ereignissen bzw. Ursachen eine Situation noch als kausal bezeichnet verwendet werden darf, ist relativ und hängt von der Anzahl aller Ereignisse und Wirkungen im System ab.
Ohne einen statistischen Beweis führen zu müssen, ist die Bestimmung einer surjektiven kausalen Spezifität im Zellprozessmodell bei Berücksichtigung sämtlicher Kausalfaktoren bzw. ihrer Teilfaktoren unmöglich, denn dazu ist die Anzahl in Betracht kommender Einzelsubstanzen viel zu hoch.
ABBILDUNG 22: ZWEI GRUNDSÄTZLICHE FORMEN KAUSALER BEZIEHUNGEN
Abbildung 22: Bei einem bijektiven Kausalzusammenhang sind immer eindeutige ‑ genauer: eineindeutige ‑ Schlüsse bzw. Rück-schlüsse möglich. 1 verursacht hier immer nur 2 und dadurch ist 2 ausschließlich auf die Wirkung von 1 zurückzuführen. Aber auch wenn eine Wirkung auf verschiedenen Ursachen beruht, dürfen Kausalbeziehungen im Sinne einer surjektiven kausalen Spezifität definiert werden, sofern die Anzahl der verschiedenen Ursachen nicht zu hoch ist. Im Beispiel können daher 5 und 7 durchaus als ursächliche Ereignisse für 6 bezeichnet werden. Anders sieht es aus, wenn die Wirkung 6 auf beispielsweise 180 oder noch mehr Ereignisse zurückzuführen wäre. Die Frage ist also, wie hoch diese Anzahl maximal sein darf, um dabei immer noch von einer eindeutigen Ursachen-Wirkungs-Beziehung sprechen zu dürfen.
Mit der Gruppierung zu acht Kausalfaktoren als maßgebliche ursächliche Substanzen(‑gruppen) ist die Ausgangslage für eine Bewertung auf den zweiten Blick dennoch möglicherweise ausreichend, um auf Grundlage der surjektiven kausalen Spezifität dennoch eindeutige Kausalitäten zu bestimmen. Denn es könnte durchaus ausreichen, die Rollen bzw. Schwächen jedes einzelnen Kausalfaktors mit Hilfe verschiedener Kriterien zu bewerten, die er als ursächliches Ereignis im Gesamtsystem spielt bzw. hat. Daraus könnte dann zumindest das Potential jedes Kausalfaktors ermittelt werden, Störungen zu verantworten. Werden dann unterschiedliche Störpotentiale festgestellt, ergäbe sich daraus eine Rangfolge der Relevanz von Kausalfaktoren.
Dazu werden Relevanzkriterien zur Kausalfaktorenbewertung benötigt. Eine Schwierigkeit besteht vor allem darin, Aussagen über die Kausalfaktorrelevanz in einem umweltisolierten geschlossenen Modell unabhängig von realen exogenen Ereignissen zu treffen.
Im Zusammenhang mit Relevanzkriterien stellen sich folgende beiden Fragen:
- Was sind sinnvolle Kriterien, mit denen der zellphysiologische Einfluss eines Kausalfaktors sicher eingeschätzt werden kann?
- Sind sinnvolle Kriterien über Eigenschaften oder Schwächen von Kausalfaktoren automatisch auch geeignete Kriterien?
3.4.2 Bewertung allgemeiner Kausalfaktorstörpotentiale (Relevanzanalyse)
Was aber charakterisiert sinnvolle und geeignete Kriterien für die Kausalfaktorenbewertung im Einzelfall? Und wie könnte ein Vergleich unterschiedlicher Relevanzen aussehen? Dies soll anhand eines einfachen Beispiels mit zwei Ereignissen, einer Wirkung und einem Relevanzkriterium erläutert werden.
Beispiel: Wer oder was ist schuld am Tod der Reisenden?
Eine Frau fährt seit Jahren an jedem Arbeitstag ausnahmslos zur gleichen Zeit mit dem Vorortzug zu ihrer Arbeitsstelle in die Innenstadt. Eines Morgens hat der Zug einen schweren Unfall aufgrund eines extrem seltenen Systemausfalls im Zug und die Frau verunglückt dabei tödlich. Das traurige Resultat, der Tod der Frau, kann jetzt auf zwei Ereignisse zurückzuführen sein: Einerseits auf den Systemausfall, andererseits darauf, dass sie den Zug überhaupt als Transportmittel benutzt hat. Sie hätte auch das Auto, das Fahrrad oder den Bus nehmen können. Welches Ereignis ist nun maßgeblich(er) bzw. relevant(er) für Ihren Tod? Oder sind beide Ereignisse gleich relevant?
Ein Kriterium zur Überprüfung der Relevanz von Ereignissen ist in diesem Beispiel das Auftreten einer außergewöhnlichen Varianz, die mit einem Geschehen (= Wirkung), in diesem Falle dem Tod der Frau, in Zusammenhang gebracht werden kann, wobei gilt: Außergewöhnliche Varianz (= außergewöhnliche Veränderung) des Ereignisses bedeutet Relevanz, keine Varianz (= keine Veränderung) des Ereignisses bedeutet Irrelevanz.
Beide Ereignisse (Systemausfall und Auswahl der Bahn als Verkehrsmittel) stehen in einem nachvollziehbaren Zusammenhang mit dem Ergebnis bzw. der Wirkung (Unfall → Tod der Frau). Die Bewertung beider Ereignisvarianzen ist sinnvoll und daher ist die Varianz auch ein sinnvolles Relevanzkriterium.
Ein Ereignis kann zweifelsfrei in keinem nachvollziehbaren Zusammenhang mit dem Ergebnis (Unfall → Tod der Frau) stehen, zum Beispiel die Kleidung der Frau. Die Ereignisvarianz der Kleidung ist daher kein sinnvolles Relevanzkriterium. Wenn die Frau am Tag des Unfalls ausnahmsweise mal ein Kostüm getragen hat, obwohl sie bis dahin immer einen Anzug bevorzugte, hat das dennoch nichts mit dem Unfall und damit ihrem Tod zu tun, auch wenn man bei einer nüchternen Betrachtung der Ereignisse diesen Eindruck haben könnte. Man spricht hier von Koinzidenz, einem zufälligen Zusammentreffen.
Da die Bewertung der Varianz sowohl des Systemausfalls als auch der Wahl des Verkehrsmittels auch praktisch möglich ist, denn die dazu notwendigen Informationen liegen vor oder können auf einfache Weise beschafft werden, sind die Varianzen beider Ereignisse jeweils auch geeignete Relevanzkriterien.
Die abschließende Bewertung ist jetzt einfach:
- Das außergewöhnlich variierende Ereignis ist hier der Systemausfall, der ein sehr seltenes, eher einzigartiges Geschehen darstellt, denn das Zugsystem arbeitete bis dahin immer korrekt und es ist nie zu Störungen gekommen.
- Die tägliche Vorortzugnutzung spielt demgegenüber nur eine untergeordnete Rolle, denn ihre Varianz ist gleich Null. Die Frau hat auf der Strecke schon immer den Zug genommen, also niemals ein alternatives Verkehrsmittel benutzt.
Ergebnis: Die Wahl des Zuges als Verkehrsmittel ist für das Resultat, den Tod der Frau, nicht relevant, wohl aber der Systemausfall. Die Zugnutzung variiert nicht, der Systemausfall stellt demgegenüber eine außergewöhnliche Variation dar.
Das Beispiel ist erweiterbar, denn man kann auch die Arbeitsstelle in der Innenstadt mit dem Zwang der täglichen Fahrt dorthin als kausal relevantes Ereignis betrachten. Denn wenn sich ihr Arbeitsplatz am Wohnort befunden hätte, wäre die Frau ebenfalls nicht in dem Unglückszug gesessen. Da ihr Innenstadtbüro jedoch ebenfalls ein nicht variierender Faktor ist, fällt auch er als irrelevant für ihren Unfalltod fort.
Was wäre jedoch, wenn sich ein Unfall nur bei einem Systemausfall mit gleichzeitiger Weichenstörung hätte ereignen können und die Weichenstörung häufiger, im Schnitt dreimal pro Jahr, auftritt und alleine folgenlos bliebe, wenn es nicht gleichzeitig zum Systemausfall kommt?
Beide Ereignisse sind relevant. Jedoch ist der Einfluss des Systemausfalls in Bezug auf das Unfallergebnis und den Tod der Bahnreisenden als höher zu bewerten, da er noch seltener auftritt als die Weichenstörung, die darüber hinaus alleine nie ein Problem verursachen könnte. Bei zwei variierenden Einflussfaktoren hat derjenige, der seltener geschieht, die höhere Varianz und damit auch die höhere Relevanz.
Für die vier analysierten Ereignisse, die in einem Zusammenhang mit dem Resultat stehen könnten, ergeben sich drei Relevanzklassen:
- Eine hohe Relevanz für den Systemausfall in Bezug auf den Unfalltod der Frau,
- eine mittlere Relevanz für die Weichenstörung in Bezug auf den Unfalltod der Frau und
- keine Relevanz für die Zugnutzung bzw. den Ort der Arbeitsstelle in Bezug auf den Unfalltod der Frau.
Kausalfaktorenbewertung auf Grundlage von Versorgungsstabilität und Störpotential
Die Varianz als Relevanzkriterium, welche im Zugbeispiel geeignet war, nützt bei der Bewertung verschiedener Kausalfaktoren nichts. Würde man Kausalfaktoren variieren, beispielsweise auf null oder annähernd null reduzieren, müssten die Zellprozesse danach komplett zusammenbrechen. Man erhält nur die triviale Aussage, dass jeder Kausalfaktor unverzichtbar für den Ablauf von Zellstoffwechselprozessen ist.
Darüber hinaus ist eine aussagekräftige Analyse der Auswirkungen unterschiedlich starker Varianzen gar nicht möglich, da es keine Erfahrungen dazu gibt und ein Vergleich aufgrund vieler charakteristischer Unterschiede zu vieler Kausalfaktoren und zu zahlreicher Einflüsse nicht möglich ist ‑ die Abläufe im Zellmodell sind dafür zu komplex.
Ein weiteres Problem besteht in der Aufgabe, das jeweilige Kausalfaktorstörpotential abstrakt und losgelöst von konkreten Wirkungen bzw. Folgen ‑ beispielsweise Erkrankungen ‑ mit Hilfe eines Modells theoretisch einzuschätzen.
Aber trotz dieser Schwierigkeiten gibt es eine Lösung, denn die Problematik der Kausalfaktorversorgung ist durch zwei Fragen charakterisiert:
- Ist eine Versorgung mit einem Kausalfaktor in der Regel sichergestellt?
- Entstehen Störpotentiale, wenn Zellen von Kausalfaktormangel oder -mängeln bedroht sind?
Versorgungsinstabilitäten und damit verbundene Störpotentiale übernehmen die Rollen von Resultaten bzw. Wirkungen, die in einem konkreten Beispiel relativ leicht zu formulieren sind und können anhand von Relevanzkriterien überprüft werden.
Fünf Relevanzkriterien zur Kausalfaktorenbewertung
Aufgrund der Limitation, Bewertungen losgelöst von konkreten Situationen wie Erkrankungen treffen zu müssen, wird die Anzahl der Relevanzkriterien allerdings überschaubar bleiben. Deren Anzahl muss allerdings ausreichen, um eine differenzierdene Bewertung zu ermöglichen.
Fünf Relevanzkriterien lassen sich zur Einschätzung von Versorgungsstabilität und Störpotential der Kausalfaktoren formulieren und mittels Punktevergabe bewerten. Trifft ein Kriterium zu, erhält es einen Bewertungspunkt. Je mehr Bewertungspunkte ein Kausalfaktor erhält, desto wahrscheinlicher sind allgemeine Zellstoffwechselstörungen im Falle von Unterversorgung oder sonstiger Mängel.
- Relevanzkriterium: Wie mutationsgefährdet ist ein Kausalfaktor?
Von Mutationen betroffene Kausalfaktoren bergen zusätzliche Risiken für den Zellstoffwechsel im Vergleich zu solchen, die nicht mutationsgefährdet sind.
Keimbahnmutationen gefährden sowohl die ursprüngliche Erbinformation als auch ncRNA. Somatische Mutationen gefährden darüber hinaus zusätzlich noch ncRNA-Codes (→ Abschnitt 3.3.8). Alle anderen Kausalfaktoren sind nicht mutationsgefährdet.
Kausalfaktorenbewertung:
Die ursprüngliche Erbinformation erhält aufgrund ihrer Gefährdung durch Keimbahnmutationen einen Bewertungspunkt, die nicht-codierenden Ribonukleinsäuren erhalten aufgrund ihrer zusätzlichen Gefährdung durch somatische DNA-Mutationen zwei Bewertungen.
- Relevanzkriterium: Ist ein Kausalfaktor in der Zelle ständig aktiv?
Stoffwechselaktive Kausalfaktoren bergen eine ununterbrochene Gefahr, bei Unter- oder Fehlversorgung Probleme zu verursachen. Einzig für die ursprüngliche Erbinformation trifft das nicht zu. Im Modell ist sie nicht stoffwechselaktiv und erfüllt einzig ihre Rolle als eine aus der Vergangenheit stammende Substanz, die einmalig Codes für Peptide und ncRNA in das Zellmodell einbringt.
Kausalfaktorenbewertung:
Im Zellbetrieb ständig aktiv sind die Faktoren Aminosäuren, Kohlenhydrate, Mikronährstoffe, Lipide/Lipoïde, ncRNA, Sauerstoff und Wasser, die alle einen Punkt erhalten.
- Relevanzkriterium: Bedeutung des Kausalfaktors für die Energieversorgung?
Energie ist eine wichtige Basis für die Lebensfähigkeit von Zellen. Neuronen haben einen besonders hohen Bedarf an Glukose und Sauerstoff. Auch kurzfristige Versorgungsprobleme können komplexe Prozessprobleme verursachen, auch mit der Folge langfristiger Schäden.
Aminosäuren erfüllen ihre Hauptaufgaben im Zusammenhang mit der Proteinsynthese. Zwar werden sie für die kurzfristige Energiebereitstellung ebenfalls verstoffwechselt, jedoch hat das in Relation zur Versorgung mit Glukose und Sauerstoff nur eine untergeordnete Bedeutung. Vergleichbares gilt für Mikronährstoffe.
Fette sind ebenfalls wichtige Energieträger, nicht jedoch im Zentralnervensystem. Ausnahme bilden nur Phasen, in denen dem Körper für längere Zeit keine Kohlenhydrate zugeführt werden, so dass Gehirn und Rückenmark auf eine Notversorgung durch Ketonkörper zurückgreifen müssen, die im Organismus als Ersatzsubstanzen gebildet werden. Dazu dienen bestimmte Amino- und Fettsäuren.
Kausalfaktorenbewertung:
Die primäre Energiequelle der Nervenzellen sind die mit der Nahrung aufgenommenen Kohlenhydrate. Der für die Energieversorgung ebenfalls wichtige Sauerstoff wird mit der Atmung zugeführt.
Amino- und Fettsäuren bzw. Mikronährstoffe erfüllen im Vergleich dazu eher untergeordnete Aufgaben bei der Energieversorgung. Das dritte Relevanzkriterium trifft daher daher vor allem auf Kohlenhydrate und Sauerstoff zu, die jeweils eine Bewertung erhalten.
- Relevanzkriterium: Welche Kausalfaktoren dominieren die Steuerung der Proteinbiosynthese?
Transkription und Translation werden auf der oberen Prozessebene durchgeführt und sind daher Bestandteile sämtlicher Zellprozesse. Kausalfaktoren, welche die Steuerung von Transkription und Translation verantworten und aufgrund von Mangel oder Mängeln ihren Funktionen nicht gerecht werden können, haben ein besonders hohes Potential, komplexe Störungen auf der oberen Zellprozessebene auszulösen, die dann auf sämtlichen Prozessebenen Probleme verursachen.
Kausalfaktorenbewertung:
Das vierte Relevanzkriterium trifft einzig auf die ncRNA zu, und nur sie erhalten daher einen Bewertungspunkt.
- Relevanzkriterium: Sind Kausalfaktormanipulationen erschwert oder unmöglich?
Alle von außen zugeführte Faktoren sind leichter zugänglich und manipulierbar, im Gegensatz zu den unzugänglicheren Nukleinsäuren der ursprünglichen Erbinformation und der ncRNA, die ausschließlich während der Meiose entstehen (ursprüngliche Erbinformation) bzw. ausnahmslos in der Zelle katalysiert werden (ncRNA).
Die Versorgung mit von außen zuzuführenden Kausalfaktoren ist darüber hinaus vergleichsweise stabiler und im Normalfall sichergestellt.
Es ist hingegen nicht möglich, die Dysfunktionalität eines Kausalfaktors direkt zu beeinflussen, der sich einem Zugriff von außen grundsätzlich entzieht, was auf die ursprüngliche Erbinformation zutrifft. oder bei dem dieser Zugriff erschwert ist bzw. im Normalfall nicht erfolgt (ncRNA).
Kausalfaktorenbewertung:
Die ursprüngliche Erbinformation und die ncRNA erhalten daher jeweils einen Punkt.
Die Punkte werden in eine Tabelle übertragen und summiert (→ Tabelle 2) und ergeben deutliche Bewertungsunterschiede. Die Relevanz eines Kausalfaktors ergibt sich aus der Summenspalte rechts; je mehr Punkte, desto relevanter ist der Kausalfaktor für den Zellstoffwechsel.
TABELLE 2: BEWERTUNG DER ALLGEMEINEN RELEVANZ VON KAUSALFAKTOREN
| KAUSALFAKTOR(-GRUPPE)
|
Mutations-gefährdet | Direkt am Zell-SW beteiligt | Unmittelbar hohe Bedeutung für die Energie-versorgung |
Dominanz Protein- biosynthese |
Ausschließlich im Zellstoff- wechsel synthetisiert |
SUMME |
|---|---|---|---|---|---|---|
Aminosäuren |
0 |
1 |
0 |
0 |
0 |
1 |
Ursprüngliche Erbinformation |
1 |
0 |
0 |
0 |
1 |
2 |
Kohlenhydrate |
0 |
1 |
1 |
0 |
0 |
2 |
Mikronährstoffe |
0 |
1 |
0 |
0 |
0 |
1 |
Nicht-codierende Ribonukleinsäuren |
2 |
1 |
0 |
1 |
1 |
5 |
Lipide/Lipoïde |
0 |
1 |
0 |
0 |
0 |
1 |
Sauerstoff |
0 |
1 |
1 |
0 |
0 |
2 |
Wasser |
0 |
1 |
0 |
0 |
0 |
1 |
Tabelle 2: Fünf Relevanzkriterien, Bewertung der acht Kausalfaktoren und Summierung der Einzelbewertungen ergeben für jeden Kausalfaktor dessen Potential, Zellprozessstörungen auszulösen. Je höher die Summe der Einzelbewertungen, desto höher ist die Wahrscheinlichkeit, für Zellstörungen (mit‑)verantwortlich zu sein.
Kausalfaktoren und ihre allgemeine zellphysiologische Bedeutung in einer Rangfolge
Aus drei verschiedenen Bewertungssummen (1, 2 und 5 Punkte) ergibt sich eine eindeutige Rangfolge der Kausalfaktoren, welche deren allgemeine zellphysiologische Bedeutung widerspiegelt.
Das Resultat dieses Kapitels lässt sich damit in einer einzigen kurzen Tabelle zusammenfassen (→ Tabelle 3). Ergänzt mit einer theoretischen Nullbewertung* ergeben sich vier Relevanzklassen.
Die für die Genregulation wichtigen nicht-codierenden Ribonukleinsäuren (ncRNA) haben somit die mit Abstand höchste Relevanz, denn sie sind nicht nur besonders störanfällig durch die Möglichkeiten erblicher und somatischer Mutationen, sie haben darüber hinaus auch ein hohes Störpotential aufgrund ihrer wichtigen Funktionen auf der oberen Zellprozessebene. Bei Zellprozessstörungen ist daher die Annahme folgerichtig, dysfunktionale ncRNA seien mit hoher Wahrscheinlichkeit an Zellprozessstörungen generell beteiligt oder sogar hauptsächlich verantwortlich.
Allgemeine zellphysiologische Bedeutung ≠ spezifische zellphysiologische Bedeutung
Die allgemeine zellphysiologische Relevanz eines Kausalfaktors darf nicht mit seiner spezifischen zellphysiologischen Relevanz verwechselt werden, denn letztere bezieht sich immer auf einen Sonderfall, der in der Regel durch eine bestimmte Erkrankung definiert wird. Dabei gilt: Die spezifische zellphysiologische Relevanz ist immer mindestens so hoch wie die allgemeine zellphysiologische Relevanz, das heißt unter bestimmten Umständen auch höher. Erst im nachfolgenden vierten Kapitel werden Kausalfaktoren unter dem Aspekt Affektiver Störungen erkrankungsspezifisch bewertet.
TABELLE 3: ALLGEMEINE ZELLPHYSIOLOGISCHE RELEVANZ DER KAUSALFAKTOREN
| Relevanzklassen
|
Kausalfaktoren |
|---|---|
Hohe Relevanz |
Nicht-codierende Ribonukleinsäuren (5) |
Mittlere Relevanz |
Ursprüngliche Erbinformation (2) |
Geringe Relevanz |
Aminosäuren (1) |
Keine Relevanz* |
--- |
Tabelle 3: Bei der Bewertung der Bedeutung der Kausalfaktoren im Zellstoffwechsel bzw. im Falle von Zellprozessstörungen lassen sich drei Abstufungen differenzieren.
*) Hinweise: Da Kausalfaktoren aufgrund ihrer Rollen im Zellstoffwechsel und gemäß Definition immer relevant sein müssen, existieren eigentlich nur drei Relevanzklassen. Es gibt jedoch Substanzen, die zellprozessunabhängig prinzipiell einen Kausalfaktor-Charakter haben. Dazu zählen die fünf Nukleinbasen Adenin, Guanin, Cytosin, Thymin und Uracil, die Bausteine von Erbinformation, Zell-DNA und RNA. Damit wird im Modell implizit ausgeschlossen, in einer Zelle könne es zu einem Basenmangel kommen, denn ein solcher ist tatsächlich eher unwahrscheinlich. Nukleinbasen werden der Vollständigkeit halber als Kausalfaktoren ohne (Modell-)Relevanz definiert.
Zum nächsten Kapitel 4 (Teil A - Zellschwachstellen) bitte hier klicken: ►